[RAG 튜토리얼 1] RAG 개념
![[RAG 튜토리얼 1] RAG 개념](/content/images/size/w1200/2025/04/GptHeader.png)
어디서 부터 시작해야 할까?
커스텀 GPT, RAG, Cursor AI, Langchain, MCP, A2A...
요즘 GPT와 AI 기반 생산성 도구들이 쏟아지듯 나오고 있습니다.
하지만 정작 저는 기술 뉴스와 유튜브 등을 통해 이들 기술을 눈으로만 익히고 실제 활용은 아직도 브라우저에서 ChatGPT 창 하나 열고 질문 -> 답변만 주고받는 방식에 머물러 있었죠.
이런 생각을 실현하기 위한 시작점으로 저는 RAG (Retrieval-Augmented Generation)를 선택했습니다.
이 시리즈는 RAG의 개념부터, GPT를 기반으로 한 나만의 인터페이스를 만들어가는 실습 과정을 초보자인 제 시선에서 직접 구현하고, 기록하는 튜토리얼입니다.
단순히 ChatGPT를 활용하는 것을 넘어서
“GPT를 내 맥락 안에 넣고, 내가 주도하는 환경”을 만들어보기 위한 여정입니다.
기초부터 하나씩, 예제 코드와 함께,
GPT 활용의 본질과 확장성을 자연스럽게 체득할 수 있도록 구성해봤습니다.
그럼 [RAG 튜토리얼 1] 개념을 시작합니다.
RAG란 무엇인가
RAG는 Retrieval-Augmented Generation의 약자입니다. 말 그대로, 검색(Retrieval)을 보강(Augmented)해서 생성(Generation)한다는 의미입니다.
기존의 GPT 같은 LLM은 질문을 받으면 자신이 훈련 중에 학습한 데이터 안에서만 답을 만들어냅니다. 하지만 이 방식에는 명확한 한계가 있습니다:
- 최신 정보가 반영되지 않음
- 특정 도메인 지식 부족
- 헛소리(환각 hallucination)를 할 수 있음
이 문제를 해결하기 위해 등장한 방식이 바로 RAG 구조입니다. RAG는 GPT가 자신의 지식에만 의존하지 않고, 외부에서 관련 정보를 검색해서 가져오고, 그 정보를 바탕으로 더 정확하고 풍부한 답변을 생성하게 합니다.
| 제목 | 내용 | 설명 |
|---|---|---|
| Retrieval | 검색 | 질문과 관련된 정보를 벡터 DB 등에서 찾아옴 |
| Augmented | 보강된 | 검색한 내용을 GPT가 받아들여 문맥으로 사용 |
| Generation | 생성 | 그 문맥을 기반으로 자연어로 응답 생성 |
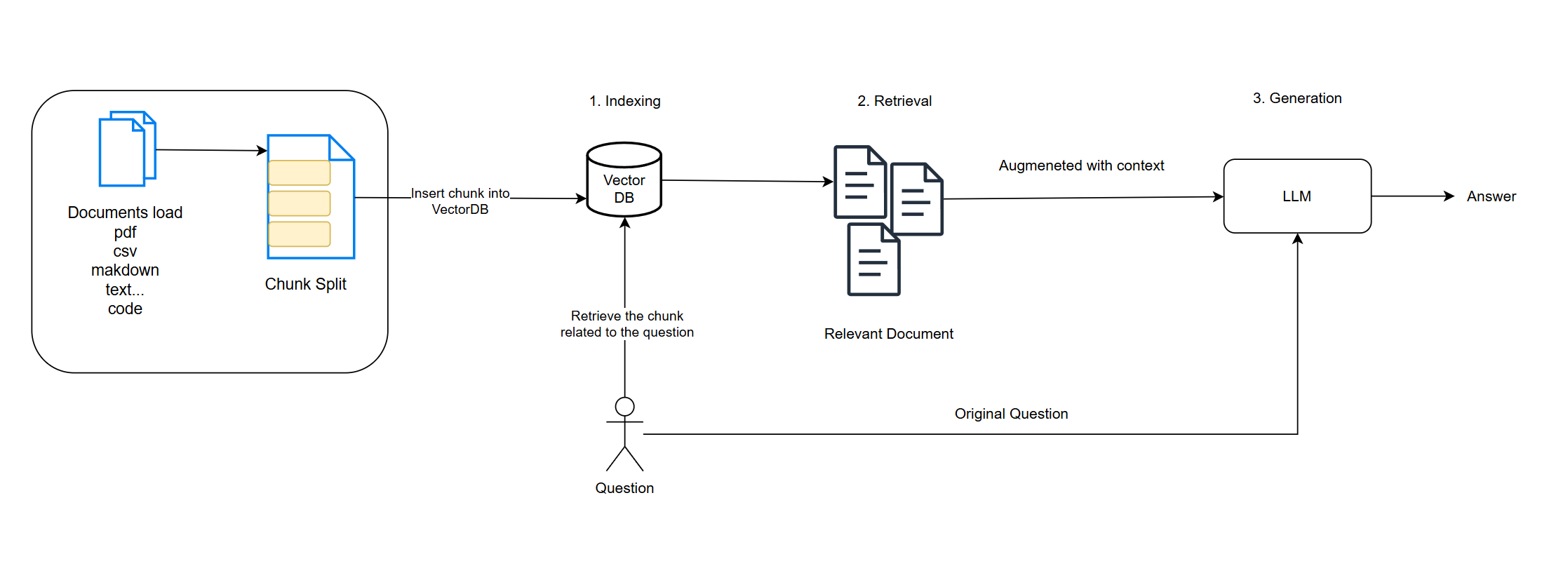
RAG 작동 구조
RAG는 아래 구조로 작동 됩니다.
1. 사용자 질문: MES 에서 생산부터 출하까지 어떤 흐름으로 이어져? 같은 질문
2. 임베딩(Embedding): 질문을 수치 벡터로 전환
3. 검색(Retrieval): 미리 저장된 벡터 DB에서 유사도가 높은 문서/코드/텍스트 검색
4. 생성(Generation): 검색된 내용을 바탕으로 GPT가 응답 생성
- 용어정리
- 임베딩: 문장을 벡터로 변환
- 청크: 원본 문서를 적절한 단위로 잘라냄
- 벡터: 숫자의 1차원 배열 [1, -2.3, 4]
- 벡터 DB에 저장한다: 벡터와 해당하는 텍스트를 함께 저장
- LLM: 수 많은 텍스트를 학습한 인공지능. ChatGPT, Gemini, LLaMA 등
- 검색: 질문벡터와 DB에 저장된 기존 벡터들의 유사도를 계산하는 것
- 결과: 가장 유사한 벡터의 텍스트(payload)를 꺼냄
예를 들어 니체의 책 '짜라투스트라는 이렇게 말했다' 책 한권을 벡터 DB에 저장한다고 할 때 적절한 청크(200~300자 기준)으로 아래와 같이 청크가 나올 수 있습니다.
Chunk 1
나는 너희가 의미를 창조하길 바란다. 인간은 극복되어야 할 무엇이다. 초인은 인간의 목적이며, 너희는 스스로를 넘어서야 한다. 인간은 다리이며, 초인을 향한 다리다.
Chunk
나는 인간의 작은 행복을 바라지 않는다. 너희는 의미 없는 만족에 안주하지 말고 스스로 운명을 만들라. 그대가 던지는 삶의 물음에 대답할 수 있어야 한다.
Chunk 3
너희는 신을 죽였다. 이제 너희는 새로운 가치를 만들어야 한다. 옛 신의 그림자 아래 살 수 없고, 새로운 태양 아래서 너희의 의미를 세워야 한다.
아래는 위 청크들을 임베딩한 예시 입니다.
| Chunk ID | 임베딩 예시 |
|---|---|
| chunk_001 | [0.031, -0.142, 0.089, 0.227, -0.013, 0.391, -0.034, ...] |
| chunk_002 | [0.043, -0.178, 0.104, 0.199, -0.027, 0.402, -0.020, ...] |
| chunk_003 | [0.025, -0.122, 0.094, 0.211, -0.011, 0.386, -0.038, ...] |
이제 이 데이터들은 벡터 DB에 아래와 같은 형태(JSON-LIKE)로 저장됩니다.
[
{
"id": "chunk_001",
"text": "나는 너희가 의미를 창조하길 바란다. 인간은 극복되어야 할 무엇이다...",
"embedding": [0.031, -0.142, 0.089, 0.227, -0.013, 0.391, -0.034, ...],
"metadata": {
"book": "짜라투스트라는 이렇게 말했다",
"chapter": "서문",
"chunk_index": 1
}
},
{
"id": "chunk_002",
"text": "나는 인간의 작은 행복을 바라지 않는다. 너희는 의미 없는 만족에 안주하지 말고...",
"embedding": [0.043, -0.178, 0.104, 0.199, -0.027, 0.402, -0.020, ...],
"metadata": {
"book": "짜라투스트라는 이렇게 말했다",
"chapter": "서문",
"chunk_index": 2
}
},
{
"id": "chunk_003",
"text": "너희는 신을 죽였다. 이제 너희는 새로운 가치를 만들어야 한다...",
"embedding": [0.025, -0.122, 0.094, 0.211, -0.011, 0.386, -0.038, ...],
"metadata": {
"book": "짜라투스트라는 이렇게 말했다",
"chapter": "서문",
"chunk_index": 3
}
}
]
임베딩 모델 선택
RAG 시스템의 핵심은 "의미를 잘 파악해서 문장 간 유사도를 정확히 비교하는 것" 으로 임베딩 품질이 매우 중요합니다.
저는 임베딩 모델로 OpenAI의 모델과 BAAI(중국, 국가연구소)의 모델인 BGE 를 비교한 후 본 튜터리얼에서는 API 호출을 통해 사용할 수 있는 OpenAI의 모델을 사용했습니다.
| 항목 | OpenAI text-embedding-3-small |
BGE bge-m3-small |
|---|---|---|
| 제작사 | OpenAI (미국) | BAAI (중국, 국가 연구소) |
| 라이선스 | 유료 ($0.02 / 1M tokens) | 무료 (Apache 2.0) |
| 벡터 차원 | 1536 | 512 |
| 다국어 지원 | 보통 수준 | 강력 (100개+ 언어, 한국어 포함) |
| 장문 지원 | 8192 tokens | 최대 8192 tokens |
| 검색 방식 | Dense (임베딩 기반) | Dense + Sparse + Multi-vector |
| RAG 적합도 | GPT 기반과 호환 최고 | 무료로 뛰어난 성능 |
| 사용 편의성 | 매우 쉬움 (API만 있으면 됨) | 설치 필요 (Hugging Face + 로컬 실행) |
| 실시간 응답 속도 | 빠름 (OpenAI 서버) | 빠름 (로컬, 단 GPU 있으면 더 좋음) |
OpenAI의 text-embedding-3-small 을 사용하면 1권 분량의 책 임베딩 비용으로 약 3원 정도 발생합니다.
임베딩 차원이란?
문장을 숫자 벡터로 표현 할 때 숫자가 몇 개 인지를 의미.
| 모델 | 벡터 차원 수 | 예시 형태 |
|---|---|---|
text-embedding-3-small |
1536차원 | [0.12, -0.87, ..., 1.02] (숫자 1536개) |
bge-m3-small |
512차원 | [0.09, -0.12, ..., 0.77] (숫자 512개) |
차원이 높을 수록 문장의 의미를 더 정교하게 표현 가능하지만, 그만큼 연산량이 많아지고 Vector DB의 저장 공간도 늘어납니다.
| 항목 | 의미 |
|---|---|
| 차원이 크다 (1536) | 유사도 비교 정확도 높아짐, 연산량 증가 |
| 차원이 작다 (512) | 속도 빠름, 경량화에 유리, 정확도는 다소 낮을 수 있음 |
| 차원 수는 통일해야 함 | Vector DB 컬렉션 안의 모든 벡터는 같은 차원이어야 함(같은 임베딩 사용) |
Langchain이란?
위에서 살펴본 RAG 작동 구조를 다시 보면
문서, 코드 저장시
- 저장하려는 문서, 코드 등을 불러오고
- 청크로 나누고
- 임베딩 -> 벡터 DB에 저장
질문시
- 질문을 임베딩
- 벡터 DB에서 관련 문서 검색
- GPT에게 문맥 전달
의 과정을 거치게 됩니다.
이 모든 걸 코드에서 직접 구현하려면 아래와 같은 복잡성이 존재합니다.
- Embedding 모델 직접 연결
- 벡터 DB API 따로 호출
- GPT API 요청 직접 구성
- 프롬프트 구조 수동 관리
이럴 때 Langchain 을 쓰면 위의 복잡한 단계를 한 줄 한 줄 명확하게 연결합니다.
Langchain은 오픈소스 기반의 RAG 프레임워크입니다. LLM과 벡터 DB, 프롬프트 등을 연결하는 체인을 구성할 수 있도록 도와주는 도구입니다.
| 기능 | 설명 |
|---|---|
| 체인 구성 | 여러 LLM 호출, 조건 분기, 도구 호출 등을 연결해서 자동화 파이프라인 생성 |
| 문서 기반 질문 응답 | RAG 구현: 질문을 벡터 DB에서 검색해 GPT로 답변 생성 |
| 에이전트 실행 | GPT가 도구를 직접 사용해 액션 실행 (계산기, 검색 등) |
| 툴 통합 | Google 검색, Python REPL, SQL 쿼리 등 외부 도구와 연동 |
| 메모리 저장 | GPT가 대화 내용을 장기 기억하도록 state 유지 |
Langchain의 대체 프레임워크로는 아래와 같은 제품들이 있습니다.
| 프레임워크 | 특징 |
|---|---|
| LlamaIndex | 문서 기반 RAG에 특화된, 더 간결하고 쉬운 대안 |
| Haystack | 전통 검색 시스템과 잘 통합되는 RAG 엔진 |
| Flowise | LangChain 기반의 GUI 도구 – 블록 연결하듯 구성 |
| Semantic Kernel | MS에서 만든 GPT 오케스트레이션 도구 (C#/Python 기반) |

- Langchain vs LlamaIndex
| 기준 | LangChain | LlamaIndex |
|---|---|---|
| 기능 확장성 | 체인 구성, 에이전트, 툴 연동 등 다양한 기능 지원 | 주로 문서 검색 & RAG에 최적화됨 |
| 러닝 커브 | 약간 복잡함 (체인 설계와 도구 사용 이해 필요) | 상대적으로 간단함 (문서 기반 QA에 집중) |
| 유연성 | 다양한 LLM & 툴 조합, 조건 흐름 처리 가능 | 문서 소스, 임베딩, 검색 등 문서 특화 구성에 강점 |
| RAG 실험용 | 여러 기능 실험에 적합 | 빠르게 문서 기반 QA 구축에 적합 |
본 튜터리얼에서는 향후 여러 LLM 호출 시나리오를 대비하여 Langchain 을 활용해서 RAG 실습을 진행 할 예정입니다.
실습준비
실습 준비로 openai의 gpt 모델 api를 사용할 수 있도록 API Key를 생성하고 결제정보를 입력해 줍니다.
- API Key 생성

https://platform.openai.com/settings/organization/api-keys
- 결제정보 입력
https://platform.openai.com/settings/organization/billing/overview
실습
- python 3.13.2
- poetry 사용
- version 2.1.1

프로젝트 생성
poetry new embedding-test
cd embedding-test
poetry add openai python-dotenv
프로젝트 루트에 .env 생성
src/embedding_test/app.py 생성

- .env 코드
OPENAI_API_KEY=dd...- app.py 코드
from openai import OpenAI
import os
from dotenv import load_dotenv
load_dotenv()
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
text = (
"나는 너희가 의미를 창조하길 바란다. 인간은 극복되어야 할 무엇이다. "
"초인은 인간의 목적이며, 너희는 스스로를 넘어서야 한다. "
"인간은 다리이며, 초인을 향한 다리다."
)
# OpenAI 임베딩 요청
response = client.embeddings.create(
input=text,
model="text-embedding-3-small"
)
embedding_vector = response.data[0].embedding
# 앞의 100개 요소만 출력
print("임베딩 벡터 (앞 100차원):")
print(embedding_vector[:100])
코드 실행
poetry run python ./src/embedding_test/app.py실행 결과

요약
- 앞으로 튜토리얼에서 사용할 기술
- LLM: OpenAI (gpt-3.5-turbo)
- Embedding: OpenAI (text-embedding-3-small)
- RAG Framework: Langchain
내용은 2편에서 이어집니다.