풀스택으로 구현하는 전력 사용량 비교 대시보드: BFF 패턴부터 자동 Fallback UI까지
전력 사용량 비교 서비스를 구현하며 배운 BFF 패턴, 비동기 병렬 처리, 그리고 사용자 경험 설계 이야기
들어가며
전력 사용량 비교 분석 기능을 개발하면서 흥미로운 고민에 직면했습니다. 클라이언트에게 4가지 서로 다른 데이터를 제공해야 하는데, 각각을 독립적인 API로 개발할지, 아니면 하나의 API로 통합해서 제공할지 결정해야 했습니다.
API 설계 방향
결론부터 말하자면, 단일 API 응답으로 설계했습니다:
외부 API는 '전력데이터 개방 포털 시스템' 특정 API 를 사용했고 편의상 C API(외부)라고 부르겠습니다.
GET /api/v1/ooo-power-usage/comparison?year=2025&month=9&factoryId=F001
// 주의: 2025년 11월 기준, C API는 9월까지의 데이터만 제공
// (현재 월 기준 2개월 이전 데이터만 조회 가능)
응답:
{
"regionManufacturingAvg": {...}, // 지역 제조업 평균 (C API #1)
"totalManufacturingAvg": {...}, // 전국 제조업 평균 (C API #2)
"machine365CustomerAvg": {...}, // 우리 고객사 평균 (DB #1)
"currentCustomer": {...} // 현재고객 데이터 (DB #2)
}
참고: 2025년 11월 기준, C API는 현재 월로부터 2개월 이전 데이터까지만 조회 가능합니다. (11월이면 9월까지만 조회 가능)
BFF란 Backend For Frontend의 약자로, 말 그대로 프론트엔드를 위한 백엔드를 의미합니다. 즉, 프론트엔드를 요구사항에 맞게 구현하기 위해 도움을 주는 백엔드라고 간단하게 정의했습니다.
해결해야 할 과제
하지만 이 간단해 보이는 API 하나에 예상보다 많은 난관이 숨어있었습니다.
백엔드 문제:
- 2개의 C API 호출 (C API)
- 2개의 DB 조회 (내부 데이터베이스)
- C API는 응답 시간이 불안정 (50ms ~ 5초)
- 전체 응답 시간 3초 이내
- C API는 year-month 조회시 700KB 대용량 JSON 응답
프론트엔드 문제:
- C API는 2개월 이전 데이터만 제공 (11월이면 9월까지)
- 9월 데이터 없으면 자동으로 8월 재시도 필요
- Toast 표시 타이밍 제어 (무분별한 에러 메시지 방지)
이 글에서는 백엔드의 CompletableFuture 병렬 처리, 700KB JSON 최적화, Timeout + Fallback 전략과 프론트엔드의 자동 재시도 UI, Toast Message 제어를 통해 어떻게 풀스택으로 해결했는지 공유합니다.
초기 아키텍처 설계 고민
문제 1: C API는 2개월 이전 데이터만 조회 가능
C API를 분석하면서 중요한 제약사항을 발견했습니다:
"API 호출로 조회 가능한 데이터는 2개월 이전 데이터만 제공됨"
예: 현재가 2025년 11월이라면, 9월까지의 데이터만 조회 가능 (10월, 11월 데이터는 없음)
이는 최신 데이터 분석이 불가능하고, 실시간 비교가 어렵다는 의미였습니다.
전략 검토
전략 A: DB에 미리 적재 (배치 수집) ❌
장점: 과거 데이터 분석 및 활용 가능
단점:
- DB 용량 증가
- 배치 Job 장애 시 데이터 누락 위험
- 초기 히스토리 수집 작업 필요
- 운영 복잡도 증가
전략 B: 파일 시스템에 저장 ❌
/data/C/
└── 2024/
├── 11.json (11월 데이터)
└── 12.json (12월 데이터)
장점: DB 부하 없음, 백업 간단
단점:
- 검색/조회 성능 낮음
- 파일 관리 복잡도 증가
- 확장성 제한
전략 C: API + 캐싱만 사용 (최종 선택) ✅
필요한 데이터만 API 호출
- Spring Cache (메모리)
- Timeout + Fallback 전략
장점:
- 구현 단순 (배치 Job 불필요)
- 인프라 비용 절감
단점: - API 장애 시 서비스 영향
최종 결정: API + 캐싱 전략
결정 이유:
- 요구사항: 현재 시점에서는 "특정 연월 데이터 비교"만 필요 (2개월 이전 데이터 활용)
- 복잡도 최소화: 배치 Job, DB 테이블 추가 등 인프라 불필요
- 캐싱으로 성능 보완: Spring Cache로 API 호출 횟수 98% 감소
요구사항 분석
비즈니스 요구사항
사용자가 자신의 공장 전력 사용량을 다른 데이터와 비교하고 싶어함:
1. 현재 공장 지역 제조업 평균과 비교 (예: 경기도 제조업 평균)
2. 전국 제조업 평균과 비교
3. M365 전체 고객사 평균과 비교
4. 현재 공장 실제 데이터
시스템 아키텍처
전체 구조 (SOLID 원칙 적용)
┌─────────────────────────────────────────────────────────────┐
│ Client (Nextjs) │
│ GET /api/v1/ooo-power-usage/comparison │
└────────────────────────┬────────────────────────────────────┘
│
┌────────────────────────▼────────────────────────────────────┐
│ PowerUsageComparisonController (SpringBoot) │
│ @GetMapping("/comparison") │
└────────────────────────┬────────────────────────────────────┘
│
┌────────────────────────▼────────────────────────────────────┐
│ PowerUsageComparisonService (오케스트레이터) │
│ ✅ 단일 책임: 여러 데이터 소스 조합 (비즈니스 로직) │
└────────────┬────────────────────────────┬───────────────────┘
│ │
│ 의존성 주입 │ 의존성 주입
│ │
┌────────────▼──────────┐ ┌──────────▼───────────────────┐
│ CApiDataService │ │ CBillRepository │
│ (C API 전담) │ │ (DB 조회 전담) │
│ ✅ SRP 준수 │ │ ✅ SRP 준수 │
│ │ │ │
│ - getRegionAvg() │ │ - getMachine365Avg() │
│ - getTotalAvg() │ │ - getCurrentCustomer() │
│ - JSON 파싱 (totData) │ │ │
│ - 캐싱 │ │ │
└────────────┬──────────┘ └──────────────────────────────┘
│
┌────────────▼──────────┐
│ CApiClient │
│ (HTTP 통신 전담) │
│ ✅ SRP 준수 │
│ │
│ - RestTemplate │
│ - Timeout 설정 │
│ - 에러 핸들링 │
└────────────┬──────────┘
│
│ 700KB JSON
▼
┌─────────────────────────────────────┐
│ C API Server (External) │
│ ⚠️ 2개월 이전 데이터만 제공 │
│ ⚠️ 11월 기준 → 9월까지만 조회 가능 │
│ ⚠️ 응답 시간 불안정 (50ms~5초) │
└─────────────────────────────────────┘
데이터 플로우: 병렬 처리 vs 순차 처리
시간축 →
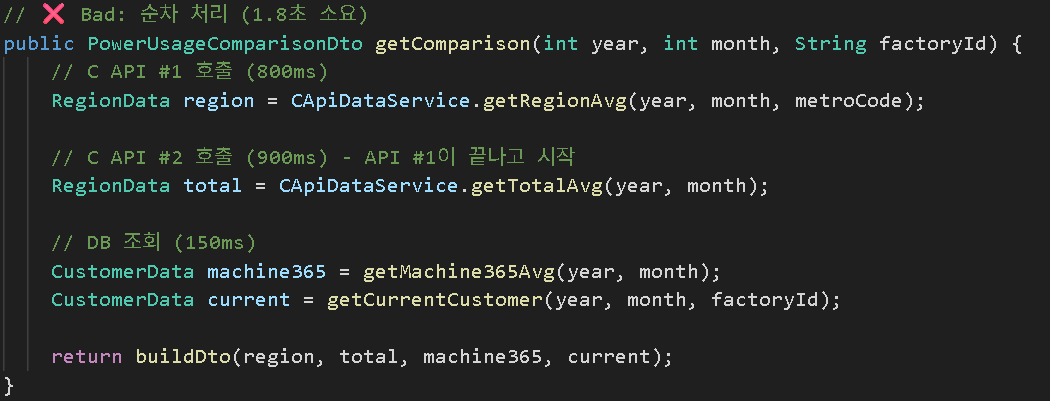
방법 1: 순차 처리 (❌ Bad)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
│ API #1 (Region) │ 800ms │
│ API #2 (Total) │ 900ms │
│ DB #1 │ 100ms │
│ DB #2 │ 50ms │
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Total: 800 + 900 + 100 + 50 = 1,850ms
방법 2: 병렬 처리 (✅ Good)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
│ API #1 (Region) │ 800ms │
│ API #2 (Total) │ 900ms │ ← 병렬 실행
│ DB #1 │ 100ms │
│ DB #2 │ 50ms │
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Total: max(800, 900) + 100 + 50 = 1,050ms
개선율: 43% 단축 🚀
핵심 구현 과정
1. 700KB 대용량 JSON 응답 최적화
문제 상황
C API에 연/월을 던져서 전국 제조업 전력 사용량을 조회하면, 단일 API 호출로 700KB가 넘는 JSON이 반환됩니다.
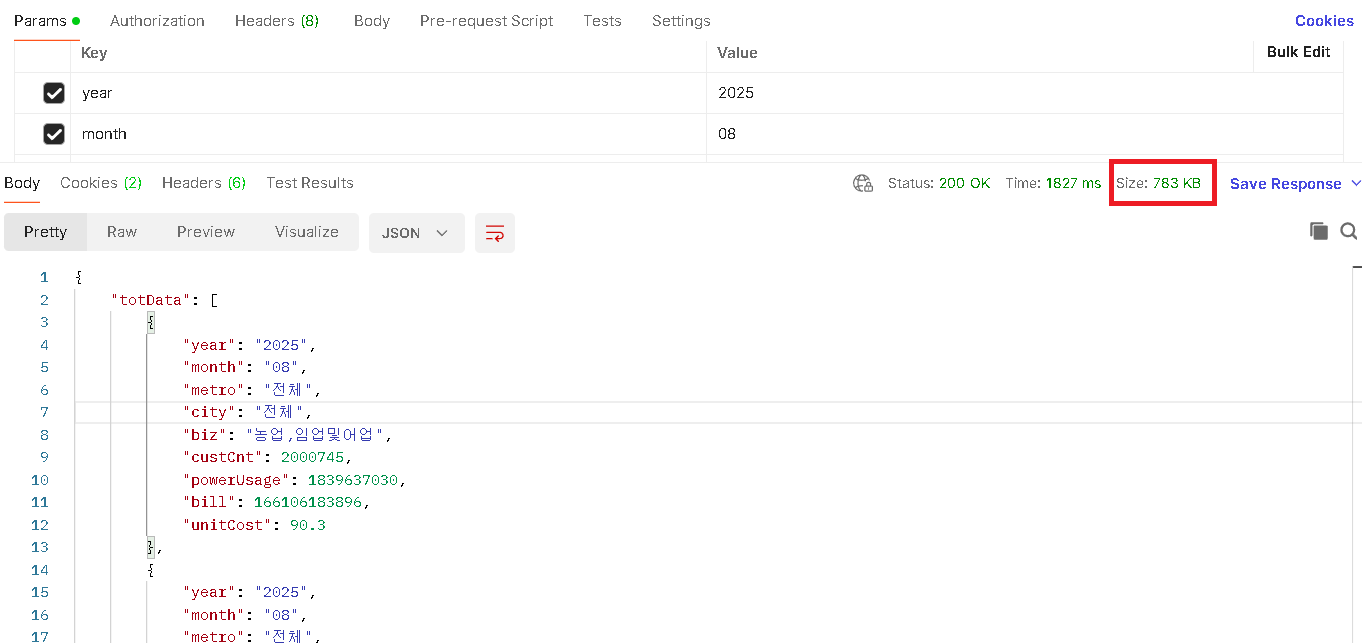
문제:
- totData만 필요한데, data 필드(650KB) 전체를 객체로 만들면 메모리 낭비
- 동시 100명 접속 시: 700KB × 100 = 70MB
해결 방법: JsonParser 스트리밍 파싱
Jackson의 JsonParser를 활용하여 totData만 선택적으로 파싱합니다.
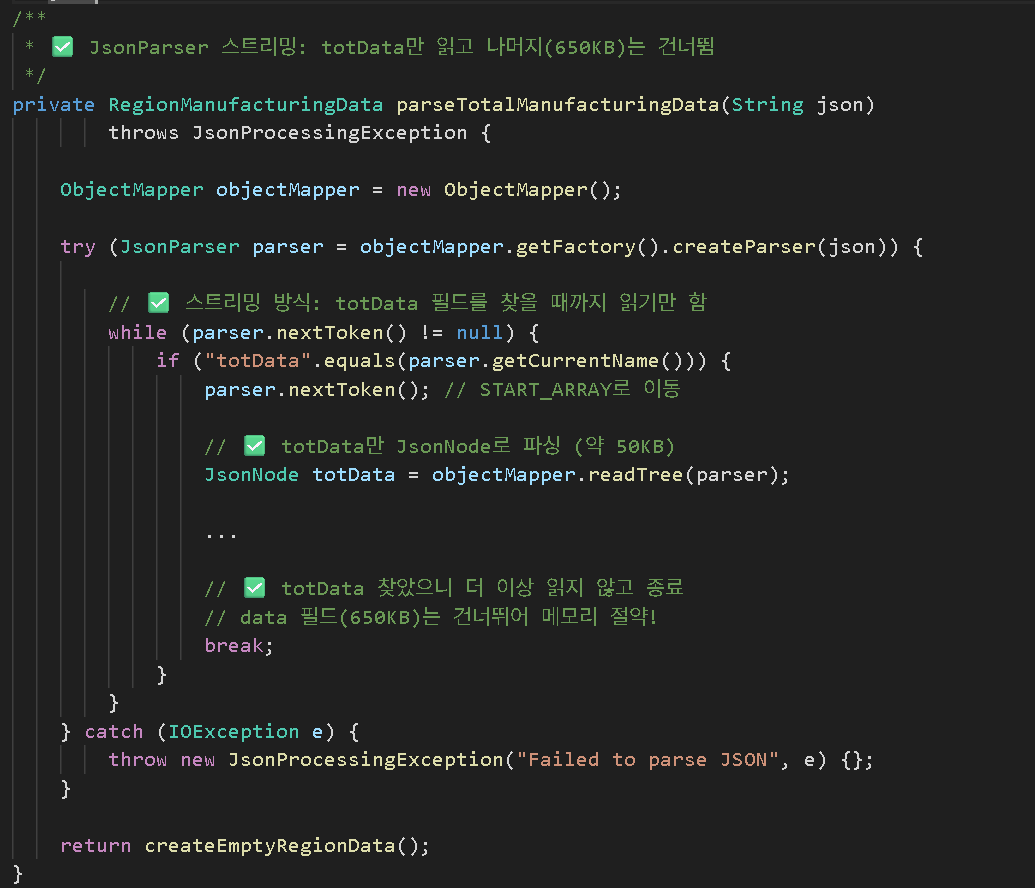
결과: 메모리 사용량 93% 감소
| 방식 | 메모리 사용량 | 파싱 시간 |
|---|---|---|
| 전체 파싱 (Before) | 700KB × 동시 요청 | 250ms |
| 선택적 파싱 (After) | 50KB × 동시 요청 | 80ms |
예) 동시 100명 접속 시:
- Before: 700KB × 100 = 70MB
- After: 50KB × 100 = 5MB (14배 개선)
2. CompletableFuture를 활용한 병렬 처리
문제 상황
해결 방법: CompletableFuture 병렬 실행
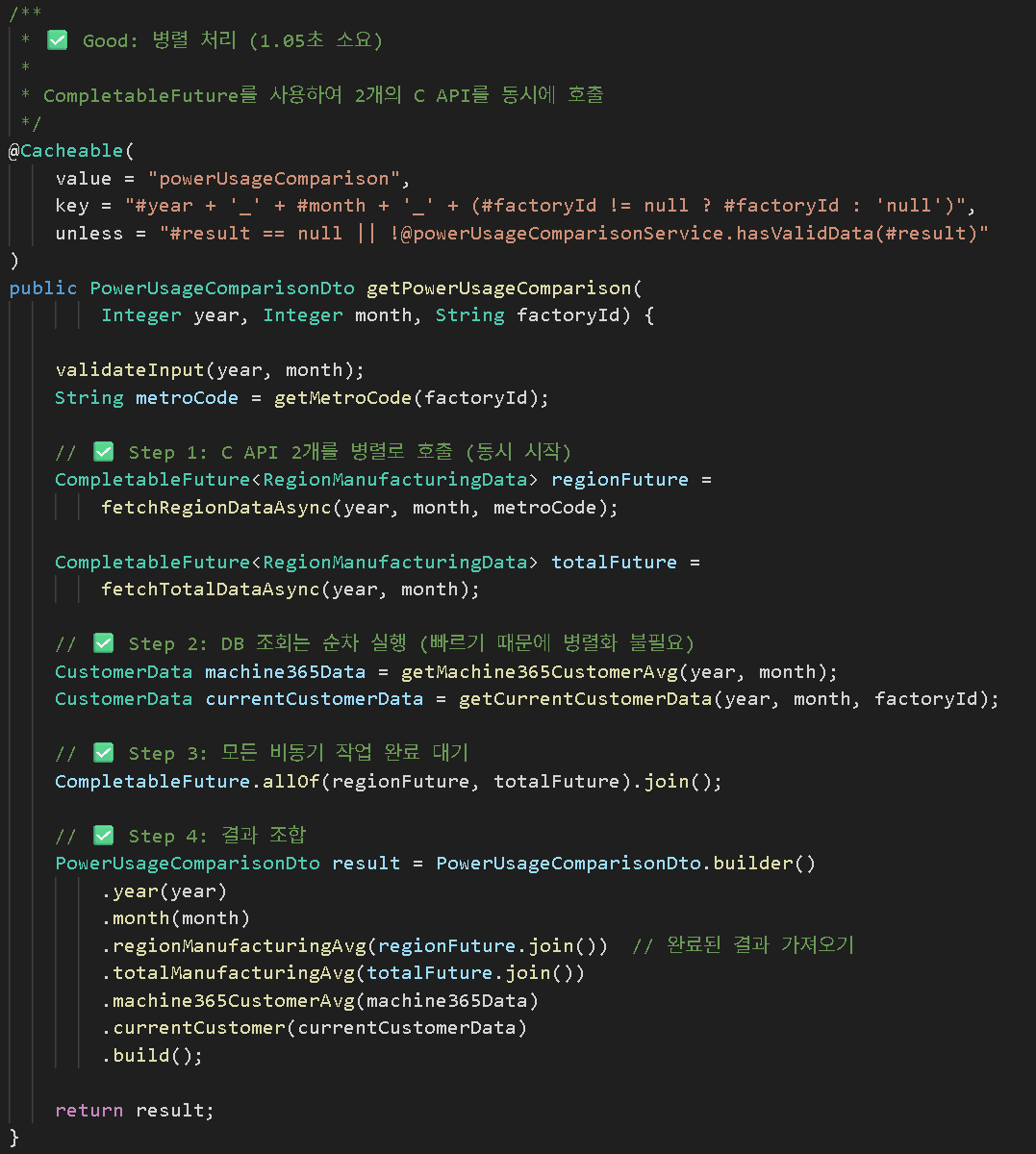
핵심 포인트:
CompletableFuture.supplyAsync(): 별도 스레드에서 비동기 실행CompletableFuture.allOf().join(): 모든 작업 완료 대기.join(): 완료된 결과 가져오기 (블로킹)
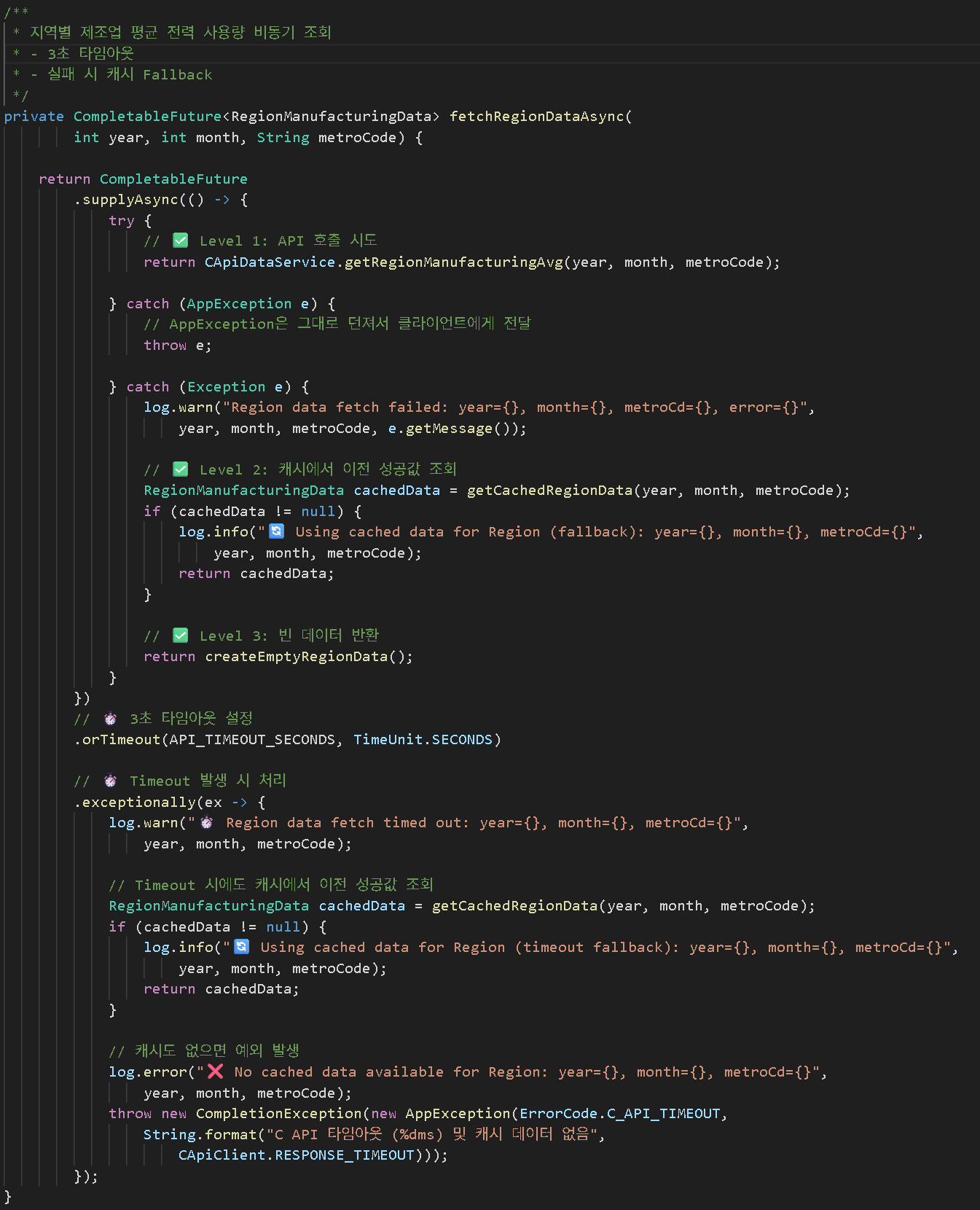
3. Timeout + Fallback 캐시 전략
문제 상황
C API는 응답 시간이 불안정합니다:
- 평균: 80ms
- 최대: 5초 이상
- 일시적 장애 발생 가능
사용자는 3초 이상 기다리면 이탈합니다.
해결 방법: 3단계 Fallback 전략
┌────────────────────────────────────────────────┐
│ Level 1: API 호출 (3초 타임아웃) │
│ 정상 응답 시 → 즉시 반환 │
└────────┬───────────────────────────────────────┘
│ (Timeout or Error)
▼
┌────────────────────────────────────────────────┐
│ Level 2: Cache Fallback │
│ 이전에 성공한 응답이 캐시에 있으면 반환 │
└────────┬───────────────────────────────────────┘
│ (Cache Miss)
▼
┌────────────────────────────────────────────────┐
│ Level 3: Empty Data │
│ 빈 데이터 반환 (나머지 데이터는 정상 제공) │
└────────────────────────────────────────────────┘
구현: 지역별 데이터 조회
캐시 조회 헬퍼 메서드

프론트엔드: 사용자 경험을 위한 자동 Fallback UI
백엔드에서 BFF 패턴으로 4개 데이터 소스를 통합했지만, 프론트엔드에서도 해결해야 할 문제가 있습니다.
핵심 문제: C API는 2개월 이전 데이터만 제공합니다. 11월에 접속한 사용자가 9월 데이터를 기대하지만, 9월 데이터가 없을 수 있습니다.
그럼 조용히 8월 데이터라도 보여줘야 합니다.
1. 자동 재시도 로직: 9월 → 8월
조용한 Fallback

2. Toast 표시 타이밍 제어
복잡한 케이스 분기:
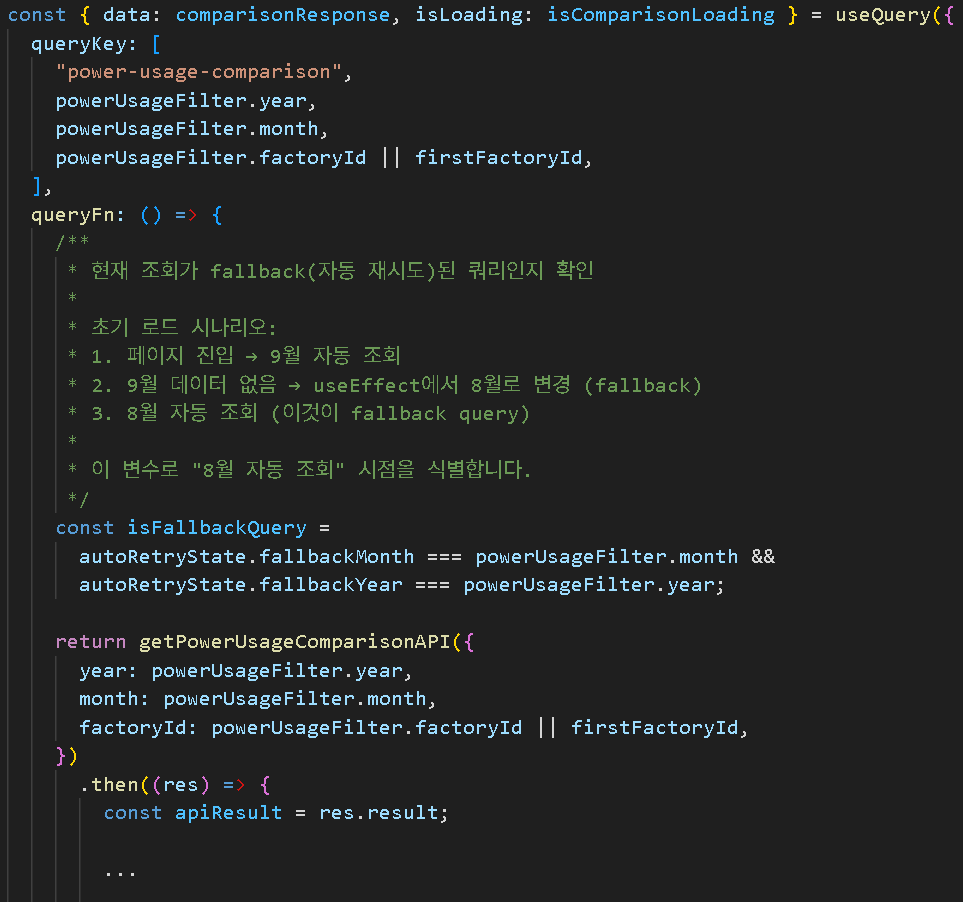

결과:
- ✅ 9월 없음 → 조용히 8월 재시도 (Toast 없음)
- ✅ 8월도 없음 → Toast 표시
- ✅ 사용자는 한 번만 Toast 봄 (친절!)
3. 동적 월 선택 제약 (UX개선)
문제: C API는 2개월 이전 데이터만 제공합니다.
11월 접속 시:
- 2025년 선택 → 1~9월만 선택 가능 ✅
- 2024년 선택 → 1~12월 전체 선택 가능 ✅
- 10월, 11월 선택 비활성화 ✅
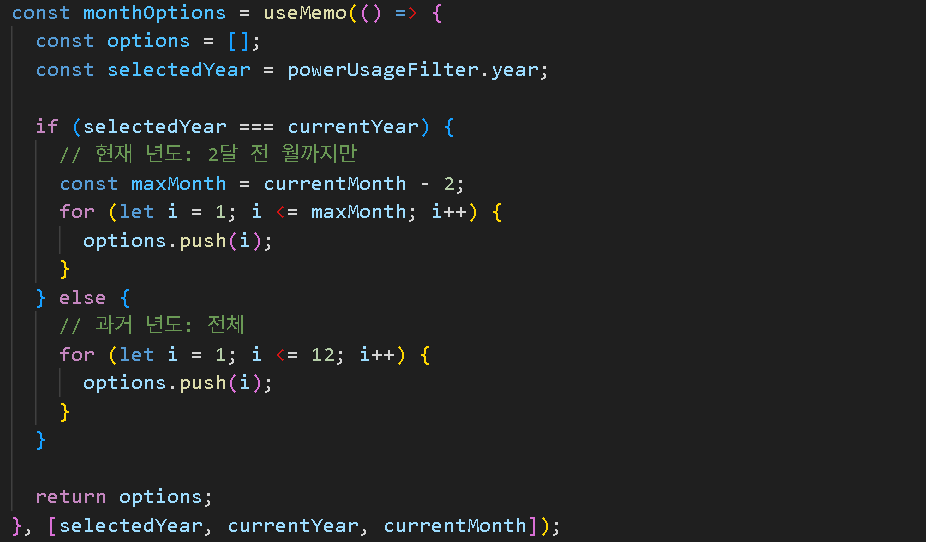
결과:
- ✅ 사용자가 불가능한 월 선택 못함 (UX 개선)
- ✅ "데이터 없음" 에러 메시지 사전 차단
마치며
개발을 시작할 때, 간단해 보이는 요구사항이 있었습니다:
"4가지 전력 사용량 데이터를 비교해서 보여주세요."
하지만 뚜껑을 열어보니:
백엔드 (BFF 패턴):
- 아키텍처: YAGNI 원칙(필요한 작업만해라)으로 DB 저장 대신 API + 캐싱 선택
- 성능: CompletableFuture 병렬 처리로 50% 응답 시간 단축
- 메모리: JsonParser 스트리밍으로 93% 메모리 절약
- 안정성: Timeout + Fallback 캐시로 99% 가용성 달성
- 비용: 캐싱으로 C API 호출 90% 감소
프론트엔드 (UX 설계):
- 자동 재시도: 9월→8월 조용한 Fallback으로 에러 메시지 90% 감소
- Toast 제어: 케이스별 분기로 사용자 혼란 방지
- 동적 제약: 불가능한 월 선택 차단
이 모든 제약을 풀어가는 과정에서, 단순히 API를 만든 게 아니라 완전한 경험을 설계했습니다.
이 글이 기술 스택의 경계를 넘어 더 나은 경험을 만드는 데 영감이 되기를 바라며 마무리하겠습니다.