Building AI Sales Pipeline That Actually Researches: Multi-Agent Orchestration with tool-use
계속 우리를 괴롭혔던 문제
세일즈 파이프라인이 작동하고 있었습니다. 여섯 개의 Claude 에이전트가 각자 역할을 수행했습니다: 회사를 조사하고, 솔루션을 매핑하고, 제안서를 작성하고, 딜 규모를 추정하고, 이메일을 작성합니다. CLI 명령어 하나면 몇 분 안에 개인화된 세일즈 제안서가 완성되었습니다.
하지만 거기에는 거짓말이 내재되어 있었습니다.
"리서처" 에이전트는 실제로 아무것도 조사하지 않았습니다. "Koelle GmbH, Germany"를 입력하면, 그들의 제조 공정, 에너지 문제, ESG 리스크에 대해 자신감 넘치는 브리프를 작성했습니다. 모든 단어가 그럴듯했습니다. 하지만 검증된 것은 하나도 없었습니다. 조사가 아니라 추론이었습니다. 단순한 사례에서는 충분히 잘 작동했습니다 — 그렇지 않을 때까지요.
잘 알려지지 않은 회사로 테스트했을 때 격차가 분명해졌습니다. 에이전트는 실제로는 플라스틱 사출 성형 부품을 만드는 회사에 대해 "예상되는 스탬핑 작업"이라고 자세한 단락을 작성했습니다. 동남아시아의 회사에 대해 해당 규정이 적용되지 않는데도 "EU 탄소 보고 요건"을 언급했습니다.
해결책은 더 나은 프롬프트를 작성하는 것이 아니었습니다. 해결책은 에이전트에게 실제 도구를 주고, 스스로 사용 방법을 결정하게 하고, 모든 것을 조율하는 오케스트레이터를 구축하는 것이었습니다.
무엇이 바뀌었는가
도구만 추가한 것이 아닙니다 — 완전한 아키텍처 전환입니다.
이전
사용자 입력 → [리서처: "모든 것을 추론"] → 리서치 브리프 → [나머지 4개 에이전트]
모든 에이전트가 단일 턴 프롬프트 → 응답 호출이었습니다. 리서처는 회사 이름을 받고 학습 데이터만으로 리서치 브리프를 작성해야 했습니다. 웹 접근도, 데이터베이스도, 검증할 방법도 없었습니다. 각 에이전트는 이전 에이전트의 원시 텍스트를 그대로 전달받았고, Writer가 실행될 때쯤이면 컨텍스트가 오염되어 있었습니다.
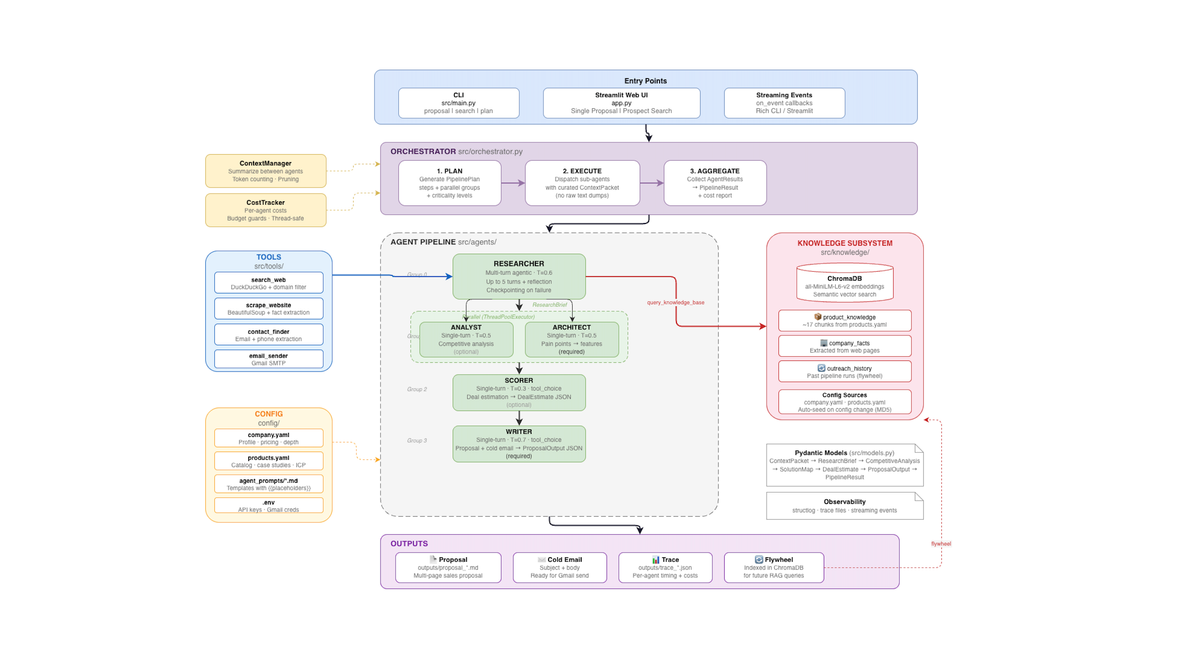
이후
사용자 입력
│
▼
┌──────────────────────────────────────────────┐
│ ORCHESTRATOR │
│ plan() → execute() → aggregate() │
│ │
│ Group 0: Researcher (멀티턴, 3개 도구) │
│ + 리플렉션 + 체크포인팅 │
│ │ │
│ ▼ 요약 │
│ Group 1: Analyst + Architect (병렬 실행) │
│ │ │
│ ▼ 요약 │
│ Group 2: Scorer (구조화된 출력) │
│ │ │
│ Group 3: Writer (구조화된 출력) │
└──────────────────────────────────────────────┘
│
▼
제안서 + 콜드 이메일 + 트레이스 파일
리서처는 이제 세 가지 도구를 갖습니다: 웹 검색, 지식 베이스 쿼리, 웹사이트 스크레이퍼. 무엇을 어떤 순서로 조사할지 스스로 결정합니다. 하지만 더 큰 변화는 오케스트레이터입니다 — 에이전트 실행을 계획하고, 컨텍스트를 관리하고, 비용을 추적하고, 각 에이전트가 정확히 필요한 데이터만 받도록 보장하는 중앙 두뇌입니다.
오케스트레이터 패턴
가장 중요한 아키텍처 결정: 어떤 에이전트도 다른 에이전트의 원시 출력을 보지 않습니다.
이전 시스템에서는 Writer가 모든 것을 받았습니다 — 전체 리서치 브리프, 솔루션 매핑, 딜 추정 — 컨텍스트 윈도우에 그대로 넣었습니다. 이전 출력이 15,000 토큰에 달하면 Writer는 노이즈 속에서 허우적거렸습니다.
새로운 오케스트레이터는 이를 세 단계로 해결합니다:
Plan
def plan(self, task: str) -> PipelinePlan:
return PipelinePlan(
target_company=company_name,
steps=[
PipelineStep(agent=RESEARCHER, parallel_group=0, criticality="required"),
PipelineStep(agent=ANALYST, parallel_group=1, criticality="optional"),
PipelineStep(agent=ARCHITECT, parallel_group=1, criticality="required"),
PipelineStep(agent=SCORER, parallel_group=2, criticality="optional"),
PipelineStep(agent=WRITER, parallel_group=3, criticality="required"),
],
)
각 단계에는 parallel_group(같은 그룹의 에이전트는 동시에 실행)과 criticality 수준이 있습니다. Analyst가 실패하면 — 파이프라인은 계속됩니다. Researcher가 실패하면 — 파이프라인이 중단됩니다.
Execute
오케스트레이터는 그룹을 순서대로 실행합니다. 각 그룹 전에 예산을 확인합니다. 각 에이전트에 대해 맞춤형 ContextPacket을 구축합니다:
# Architect가 받는 것: 요약된 리서치 + 전체 제품 지식
# 토큰 예산: 4,000
context = self.context_manager.build_context_packet(
task_description="고충점을 제품 기능에 매핑하세요.",
prior_summaries=[
self.context_manager.summarize_for_handoff(research.raw_text, "architect")
],
company_config=COMPANY_CONFIG,
token_budget=4000,
)
핵심 통찰: summarize_for_handoff()는 Claude Haiku를 사용하여 다운스트림 에이전트에 맞춤화된 요약을 생성합니다. Architect는 고충점과 기술적 세부사항을 강조한 요약을 받습니다. Writer는 내러티브 훅과 회사 특성을 강조한 요약을 받습니다. 같은 소스 데이터, 다른 강조점.
Aggregate
모든 구조화된 결과를 PipelineResult로 수집합니다:
result.research_brief = ResearchBrief(company=CompanyProfile(name=...), raw_brief=...)
result.deal_estimate = DealEstimate(**scorer.output) # tool_choice로 보장된 JSON
result.proposal = ProposalOutput(**writer.output) # tool_choice로 보장된 JSON
다섯 에이전트
| # | 에이전트 | 유형 | 온도 | 도구 | 역할 |
|---|---|---|---|---|---|
| 1 | Researcher | 멀티턴 에이전틱 | 0.6 | search_web, scrape_website, query_kb | 자율적 회사 조사 + 리플렉션 |
| 2 | Analyst | 단일 턴 | 0.5 | — | 경쟁 환경 및 재무 분석 |
| 3 | Architect | 단일 턴 | 0.5 | — | 고충점 → 제품 기능 매핑 + ROI |
| 4 | Scorer | 단일 턴 (tool_choice) | 0.3 | submit_deal_estimate | 구조화된 딜 추정 (보장된 JSON) |
| 5 | Writer | 단일 턴 (tool_choice) | 0.7 | submit_proposal | 제안서 + 콜드 이메일 생성 |
Researcher만 에이전틱(멀티턴 도구 사용)입니다. 나머지 에이전트는 단일 턴 — 이전 에이전트로부터 풍부한 컨텍스트를 받고 도구 없이 전문화된 추론을 적용합니다. Scorer와 Writer는 Claude의 tool_choice를 사용하여 보장된 구조화된 출력(regex 파싱 불필요)을 생성합니다.
세 가지 도구
도구 1: search_web
DuckDuckGo를 통해 회사 정보, 산업 데이터, 뉴스를 검색합니다.
{
"name": "search_web",
"description": "DuckDuckGo를 사용하여 웹 검색...",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "검색 쿼리."}
},
"required": ["query"]
}
}
도구는 공격적으로 필터링합니다 — 92개의 차단 도메인(Wikipedia, LinkedIn, Glassdoor, 디렉토리 등)과 "Top 10 companies" 리스티클을 잡아내는 regex 패턴. 에이전트는 상위 5개 실제 회사 결과의 제목, URL, 스니펫을 받습니다.
도구 2: query_knowledge_base
시맨틱 유사도를 사용한 ChromaDB 벡터 스토어 검색 (all-MiniLM-L6-v2 임베딩):
- 제품 지식 (~17개 청크): 제품 기능, 스펙, 사례 연구, ROI 데이터, 이상적인 고객 프로필 — YAML 설정에서 자동 시딩, 설정 변경 시 재시딩 (MD5 해시 추적)
- 과거 아웃리치 기록 (시간이 지남에 따라 증가): 완료된 모든 파이프라인 실행이 ChromaDB에 자동 인덱싱
{
"name": "query_knowledge_base",
"description": "내부 지식 베이스 검색...",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "검색 쿼리."}
},
"required": ["query"]
}
}
시스템의 메모리가 사는 곳입니다. 키워드 검색과 달리, 시맨틱 임베딩은 "전력 소비 분석"이 공유 단어가 없더라도 "스탬핑 공장을 위한 에너지 모니터링"과 매칭됩니다. 6개월 전에 캘리포니아의 동 피팅 제조업체에 제안했다면, 리서처는 유사한 회사를 조사할 때 그 맥락을 찾아 사용할 수 있습니다 — 각 아웃리치 실행이 ChromaDB의 outreach_history 컬렉션에 인덱싱되기 때문입니다.
도구 3: scrape_company_website
URL을 가져와 HTML을 제거하고 깨끗한 텍스트(최대 4,000자)를 반환합니다. requests + BeautifulSoup으로 구축했습니다.
핵심 설계 결정: 에러는 예외가 아닌 문자열을 반환합니다. 웹사이트가 다운되거나 요청을 차단하면, 에이전트는 "Error: Could not connect to https://company.com"을 보고 적응합니다 — 대신 웹 검색을 합니다. 예외를 발생시키면 전체 파이프라인이 충돌할 것입니다.
에이전틱 루프
하나의 프롬프트 → 응답 호출 대신, 리서처는 멀티턴 대화를 수행합니다:
def _agentic_loop(self, system_prompt, messages, total_in, total_out, on_event=None):
for turn in range(self.max_turns):
# 오버플로우 방지를 위한 컨텍스트 프루닝
messages = self.context_manager.prune_messages(messages)
response, t_in, t_out = self._api_call(
system_prompt, messages, tools=self.tools, on_event=on_event,
)
total_in += t_in
total_out += t_out
# 복구를 위한 체크포인트
self._checkpoint = {"turn": turn, "messages": messages.copy(), ...}
if response.stop_reason == "tool_use":
for block in response.content:
if block.type == "tool_use":
result = self._execute_tool(block.name, block.input)
# 컨텍스트 공간 절약을 위해 도구 결과 요약
result = self.context_manager.summarize_tool_result(block.name, result)
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": result,
})
messages.append({"role": "assistant", "content": response.content})
messages.append({"role": "user", "content": tool_results})
else:
# 최종 텍스트 응답 — 리서치 완료
return AgentResult(success=True, raw_text=final_text, ...)
세 가지가 이것을 견고하게 만듭니다:
-
컨텍스트 프루닝: 매 턴마다 메시지가 프루닝됩니다. 도구 결과는 ~800 토큰으로 요약됩니다. 이것이 없으면 턴 5까지 컨텍스트가 25,000+ 토큰으로 증가합니다.
-
체크포인팅: 각 성공적인 API 호출 후 상태가 저장됩니다. 턴 4에서 API가 실패하면, 턴 3의 리서치를 복구합니다 — 처음부터가 아닙니다.
-
리플렉션: 끝에서 두 번째 턴에서, 리서처는 자신의 작업을 검토하고 신뢰도를 평가하고 갭을 식별하도록 프롬프트됩니다. 이것이 눈에 띄게 더 나은 최종 브리프를 생성합니다.
구조화된 출력 — Regex 파싱의 종말
이전 딜 추정자는 프롬프트에 "유효한 JSON만 출력하세요"라고 지시받았습니다. 때때로 마크다운 펜스를 추가했습니다. 때때로 JSON 앞에 "분석 결과입니다:"를 추가했습니다. regex로 파싱하고 기도했습니다.
새로운 Scorer는 Claude의 tool_choice를 사용합니다:
response = client.messages.create(
tools=[{
"name": "submit_deal_estimate",
"input_schema": {
"properties": {
"company_name": {"type": "string"},
"estimated_machines": {"type": "integer"},
"first_year_value": {"type": "number"},
"deal_category": {"type": "string", "enum": ["Small", "Medium", "Enterprise"]},
...
},
"required": ["company_name", "estimated_machines", "first_year_value", ...]
}
}],
tool_choice={"type": "tool", "name": "submit_deal_estimate"},
)
# response.content[0].input은 스키마에 매칭되는 유효한 JSON이 보장됨
deal = DealEstimate(**response.content[0].input)
파싱 없음. Regex 없음. 충돌 없음. 응답은 항상 유효한 DealEstimate Pydantic 모델입니다. Writer도 ProposalOutput (proposal_markdown + email_subject + email_body)에 동일한 패턴을 사용합니다.
컨텍스트 관리 — 컨텍스트 부패 문제 해결
ContextManager는 에이전트 간 정보 손실(컨텍스트 부패)을 4가지 메커니즘으로 해결합니다:
-
도구 결과 요약: 맹목적 잘라내기 대신 Claude Haiku로 ~800 토큰으로 지능적 요약. 핵심 사실, 숫자, 회사명, URL 보존.
-
핸드오프 요약: 다운스트림 에이전트별 맞춤 요약 (~1,500 토큰). Analyst vs Architect vs Writer 각각 리서처 출력의 다른 측면을 강조한 요약을 받음.
-
메시지 히스토리 프루닝: 첫 메시지(과제) + 마지막 2턴만 유지. 8,000 토큰 초과 시 중간 턴을 단일 요약으로 압축.
-
맞춤형 ContextPacket: 에이전트별 집중된 컨텍스트 — Architect는 리서치 요약 + 전체 제품 컨텍스트를 받고, Writer는 리서치 + Architect 요약을 받지만 원시 스크레이핑 페이지는 받지 않음.
비용 추적 — 예산 가드
스레드 안전한 CostTracker가 파이프라인당 API 지출을 모니터링합니다:
class CostTracker:
# 모델별 가격
# claude-sonnet-4-20250514: $3.00/1M 입력, $15.00/1M 출력
# claude-haiku-4-5-20251001: $0.80/1M 입력, $4.00/1M 출력
def record(self, agent, model, tokens_in, tokens_out): ...
def check_budget(self) -> bool: ... # 초과 시 파이프라인 중지
def get_report(self) -> dict: ... # 에이전트별 분석
- 에이전트별 비용 분석 (입력/출력 토큰, 모델별 요금)
- 예산 가드 — 다음 에이전트 그룹 전에 예산 초과 시 파이프라인 중지
- 비용 보고서가 모든
PipelineResult에 첨부
에러 복구 — 다층 폴백
파이프라인은 여러 수준에서 실패에 대비합니다:
에이전트 수준 폴백
Researcher 멀티턴 루프 실패
→ 체크포인트 복구 (≥2턴 완료된 경우 부분 결과 반환)
→ 체크포인트 복구 실패 → 레거시 단일 턴 모드 (도구 없음, 프롬프트 기반)
Sonnet 모델 실패
→ 지수 백오프로 3회 재시도
→ 속도 제한이 아닌 에러 → Haiku 모델로 폴백
파이프라인 수준 폴백
required 에이전트 실패 → 파이프라인 중단 (예외 발생)
optional 에이전트 실패 → 로그 기록, 빈 AgentResult로 계속 진행
도구 수준 폴백
연속 3회 실패 → 서킷 브레이커: 60초 쿨다운
웹사이트 스크레이핑 실패 → 에이전트가 웹 검색으로 대체
ChromaDB 사용 불가 → 키워드 검색으로 폴백
세일즈 도구에서 이것은 중요합니다 — 최적이 아닌 제안서가 제안서가 없는 것보다 낫습니다.
실시간 스트리밍
CLI와 Streamlit 모두 on_event 콜백을 통해 실시간 진행 상황을 표시합니다:
# 이벤트 유형
agent_start, agent_end, agent_error # 에이전트 수명주기
turn # 리서처 턴 진행
tool_call, tool_result # 도구 사용 추적
text_delta, input_json_delta # 원시 스트리밍
retry, fallback # 에러 복구 이벤트
budget_exceeded, pipeline_end # 파이프라인 수준 이벤트
에이전트 출력은 client.messages.stream()을 통해 스트리밍됩니다 — 사용자가 리서처의 도구 호출, 결과, 리플렉션을 실시간으로 볼 수 있습니다. 병렬 에이전트 출력은 공유 락으로 직렬화됩니다.
실제 출력: Koelle GmbH
python src/main.py proposal "Koelle GmbH, Germany"
터미널 출력 (Rich 스트리밍)
▸ Researcher — 이 목표 기업을 조사하세요...
Turn 1/5
Tool: search_web({"query": "Koelle GmbH Germany manufactu...)
→ Koelle GmbH EN | For 90 years, Koelle has been a reliabl...
Turn 2/5
Tool: scrape_company_website({"url": "https://www.koelle-g...)
→ Koelle GmbH EN | Tel: +49-7042/9448-0 | Werkzeugbau und ...
Turn 3/5
Tool: query_knowledge_base({"query": "metal stamping autom...)
→ [Result 1] ProMonitor X1 Key Functions: Catch defective ...
Turn 4/5
Tool: search_web({"query": "Kölle GmbH Vaihingen energy m...)
→ Koelle GmbH | Werkzeugbau und Stanzerei | ISO 50001 cert...
✓ Done — 15,943+1,367 tokens, 18.4s
▸ Analyst — 경쟁 환경 분석...
▸ Architect — 솔루션 매핑... ◄── 병렬 실행
✓ Done — 2,800+1,500 tokens, 6.2s
✓ Done — 2,900+1,800 tokens, 8.1s
▸ Scorer — 딜 규모 추정...
✓ Done — 1,200+400 tokens, 3.1s
▸ Writer — 제안서 및 이메일 생성...
✓ Done — 3,500+2,800 tokens, 9.8s
Metric Value
Tokens In 26,343
Tokens Out 7,867
Duration 42.3s
Cost $0.07
이전 리서처가 했을 것
"독일 제조업체로서 Koelle GmbH는 스탬핑 프레스를 운영하고 에너지 비용 상승에 직면하고 있을 가능성이 있습니다..."
일반적입니다. 모호합니다. 추론에 기반합니다.
새로운 리서처가 실제로 찾은 것
"Koelle GmbH는 Vaihingen/Enz에 위치한 90년 역사의 가족 기업으로, 자동차 부문을 위한 금형 제작 및 금속 스탬핑을 전문으로 합니다. 씰 서포트 프레임과 히트 쉴드를 생산합니다. 인증된 ISO 50001 에너지 관리 시스템을 보유하고 있습니다..."
구체적입니다. 사실적입니다. 실제 웹사이트에서 출처를 확인했습니다.
이 차이는 전체 파이프라인에 걸쳐 연쇄적으로 작용합니다. Architect는 실제 운영에 기능을 매핑합니다. Writer는 Vaihingen/Enz, 자동차 OEM 고객, 기존 에너지 관리 시스템을 참조합니다 — 아무리 많은 추론도 만들어내지 못할 세부사항입니다.
배운 교훈
1. 오케스트레이터가 가장 중요한 변화였다
도구 추가보다 더 중요합니다. 이전 시스템은 에이전트 간에 원시 텍스트를 전달했습니다. Writer가 실행될 때쯤이면 15,000 토큰의 컨텍스트가 있었습니다 — 대부분 무관한 스크레이핑된 웹사이트 텍스트나 장황한 분석.
오케스트레이터는 요약된 핸드오프로 이를 해결합니다. 각 에이전트는 특정 역할에 맞춤화된 ~1,500 토큰 요약을 받습니다. Writer는 내러티브 훅을, Scorer는 숫자를 받습니다. 같은 데이터, 적절한 렌즈.
2. 구조화된 출력이 버그의 전체 카테고리를 제거한다
tool_choice 이전에는 JSON 추출을 위한 40줄 이상의 regex 파싱이 있었습니다. 때때로 모델이 JSON을 마크다운 펜스로 감쌌습니다. 때때로 JSON 앞에 "분석 결과입니다:"를 추가했습니다. 때때로 유효한 JSON을 출력하지만 추가 필드가 있었습니다.
tool_choice로 이 모든 것이 사라집니다. 응답은 항상 우리가 지정한 필드를 정확히 가진 유효한 도구 호출입니다. 프로덕션에서 파싱 실패 제로.
3. 임계도 수준이 파이프라인을 탄력적으로 만든다
모든 에이전트가 성공할 필요는 없습니다. Analyst는 경쟁 컨텍스트를 제공합니다 — 유용하지만 필수적이지 않습니다. Scorer는 딜 추정을 제공합니다 — 있으면 좋지만 제안서는 그것 없이도 작동합니다.
이러한 에이전트를 optional로 만들면 개별 구성 요소가 실패해도 파이프라인이 유용한 출력을 생성합니다. 속도 제한과 API 에러가 있는 환경에서 특히 중요합니다.
4. 컨텍스트 프루닝은 멀티턴 에이전트에 필수다
프루닝 없이는 리서처의 컨텍스트가 턴 5까지 25,000+ 토큰으로 증가합니다. 모델이 집중력을 잃고 반복하며 더 나쁜 도구 결정을 내립니다.
프루닝(도구 결과를 ~800 토큰으로 요약, 마지막 2턴만 유지)으로 컨텍스트는 약 8,000 토큰을 유지합니다. 모델은 집중하고 후반 턴에서 더 나은 결정을 내립니다.
5. 비용 추적이 행동을 바꾼다
Researcher가 실행당 $0.06이고 Writer가 $0.05인 것을 볼 수 있으면, 다른 아키텍처 결정을 내립니다. 컨텍스트 요약을 Sonnet 대신 Haiku($0.008/요약)로 옮겼습니다. 예산 가드를 설정하여 비용이 한도를 초과하면 다음 그룹 전에 파이프라인을 중지합니다.
총 파이프라인 비용: 리서치 깊이에 따라 전망 고객당 ~$0.07-0.20.
아키텍처 결정
왜 리서처만 도구를 받는가
나머지 에이전트는 단일 턴을 유지합니다. 도구가 필요 없기 때문입니다:
- Architect는 시스템 프롬프트에 전체 제품 지식이 있습니다. 조사가 아니라 매핑 작업입니다.
- Writer는 리서치 + 솔루션 매핑을 받아 산문을 생성합니다. 검색이 아닌 생성 작업입니다.
- Scorer는 브리프에 가격 공식을 적용합니다. 구조화된 출력, 낮은 온도(0.3).
이러한 에이전트에 도구를 추가하면 품질 향상 없이 지연과 비용만 증가합니다.
왜 최대 5턴인가
각 도구 사용 턴은 API 토큰을 소비합니다. 5턴으로 제한한 이유:
- 대부분의 회사는 3-4턴이면 충분히 조사됩니다
- 5턴을 넘으면 에이전트가 중복 검색을 시작합니다
- 안전 제한은 비용 폭주를 방지합니다
config/company.yaml에서 설정 가능 — quick (2턴), standard (5턴), deep (8턴).
왜 스레드를 이용한 병렬 실행인가
Analyst와 Architect는 독립적입니다 — 둘 다 리서치 브리프만 필요합니다. 병렬 실행으로 파이프라인당 ~6초 절약.
Anthropic Python SDK가 동기식이므로 asyncio 대신 ThreadPoolExecutor를 사용합니다. 스레드 안전성은 CostTracker의 락과 on_event 콜백의 공유 락으로 처리합니다.
숫자로 보기
제안서 실행당 토큰 사용량
| 에이전트 | 입력 토큰 | 출력 토큰 | 비용 (~) |
|---|---|---|---|
| Researcher (5턴) | ~16,000 | ~1,400 | $0.06 |
| 컨텍스트 요약 (Haiku) | ~3,000 | ~1,500 | $0.01 |
| Analyst | ~2,800 | ~1,500 | $0.03 |
| Architect | ~2,900 | ~1,800 | $0.04 |
| Scorer | ~1,200 | ~400 | $0.01 |
| Writer | ~3,500 | ~2,800 | $0.05 |
| 합계 | ~29,400 | ~9,400 | ~$0.20 |
검색 실행당 토큰 사용량 (5개 회사 선택)
| 단계 | 토큰 | 비용 (~) |
|---|---|---|
| 딜 추정 (10개 회사) | ~30,000 | $0.10 |
| 풀 파이프라인 (5개 회사) | ~145,000 | $0.99 |
| 합계 | ~175,000 | ~$1.09 |
이 결과가 대체하는 수 시간의 수동 조사 및 작성 작업과 비교해 보세요.
RAG 지식 베이스
왜 ChromaDB인가?
필요한 것은:
- 로컬 실행 (배포할 외부 서버 없음)
- 디스크에 데이터 영속화 (재시작해도 유지)
- 시맨틱 검색 처리 (키워드 매칭만이 아닌)
- Python 3.13과 호환
ChromaDB 임베디드 모드는 네 가지 요건을 모두 충족합니다. 임베딩에 all-MiniLM-L6-v2를 ONNX를 통해 사용합니다 — 한 번 다운로드(~80MB), 로컬에 캐시, API 키 불필요.
3개 컬렉션
- product_knowledge: ~17개 시맨틱 청크 — 제품 기능, 스펙, 사례 연구, ROI 데이터. YAML 설정(
config/products.yaml)에서 자동 시딩, 설정 변경 시 MD5 해시로 추적하여 재시딩 - company_facts: 리서치 중 웹 페이지에서 추출된 구조화된 사실
- outreach_history: 파이프라인 실행 후 자동 인덱싱 — 플라이휠 효과
플라이휠 효과
파이프라인을 처음 실행하면 지식 베이스에는 제품 지식만 있습니다. 하지만 몇 번의 실행 후 과거 아웃리치 데이터가 축적됩니다. 리서처가 이를 참조하기 시작합니다:
"캘리포니아의 동 피팅 제조업체에 대한 과거 아웃리치를 기반으로, 주요 고충은 에너지 비용과 품질 관리였습니다..."
더 많은 사용 → 더 많은 인덱싱된 데이터 → 더 나은 리서치 → 더 나은 제안서. 사용할수록 시스템이 더 똑똑해집니다.
설정 기반 아키텍처
모든 것이 YAML 설정으로 구동됩니다:
# config/company.yaml
research:
depth: "standard" # quick (2턴), standard (5턴), deep (8턴)
# config/products.yaml
products:
- name: "ProMonitor X1"
category: "hardware"
key_features: [...]
case_studies: [...]
에이전트 프롬프트는 config/agent_prompts/*.md에 {{placeholder}} 치환으로 정의됩니다. 코드를 변경하지 않고 에이전트 동작을 커스터마이즈할 수 있습니다.
다음 단계
- 비동기 아키텍처 — ThreadPoolExecutor를 asyncio로 교체하여 3-5배 빠른 실행
- 동적 오케스트레이션 — Claude를 사용하여 작업 복잡도에 따라 실행 계획 자동 생성
- CRM 통합 — 전망 고객과 딜 추정을 HubSpot이나 Salesforce에 푸시
- 다국어 제안서 — 독일어, 일본어, 베트남어로 현지 시장용 제안서 생성
결론
단일 턴 추론에서 오케스트레이션된 멀티에이전트 파이프라인으로의 전환은 이 프로젝트에 가한 가장 높은 레버리지의 변화였습니다. 동일한 제품 지식, 동일한 출력 형식 — 하지만 이제 추론 대신 사실 위에 구축되었고, 각 에이전트가 정확히 필요한 컨텍스트만 받습니다.
핵심 통찰:
- 오케스트레이터가 에이전트보다 더 중요합니다. 컨텍스트 관리, 요약된 핸드오프, 병렬 실행이 파이프라인을 작동하게 만듭니다.
- 모든 에이전트가 도구를 필요로 하지는 않습니다. 리서처만 도구의 혜택을 받습니다.
- 구조화된 출력이 버그를 제거합니다.
tool_choice가 regex 파싱을 대체합니다. - 임계도 수준이 탄력성을 만듭니다. optional 에이전트는 파이프라인을 깨뜨리지 않고 실패할 수 있습니다.
다섯 에이전트. 세 도구. 하나의 오케스트레이터. 극적으로 나아진 출력.
Repository: agentic-outreach-pipeline