대량 엑셀 다운로드

대량 엑셀 다운로드를 구현하기 위해 시도한 시행착오를 정리해보았습니다 😊
기존 엑셀 다운로드 구성
- Machine365의 '기록' 페이지를 렌더링 하기 위한 API 사용하여 데이터를 가져오고 가져온 데이터를 브라우저에서 엑셀파일로 구성해서 다운로드가 되는 방식이었습니다
기존 다운로드의 문제점
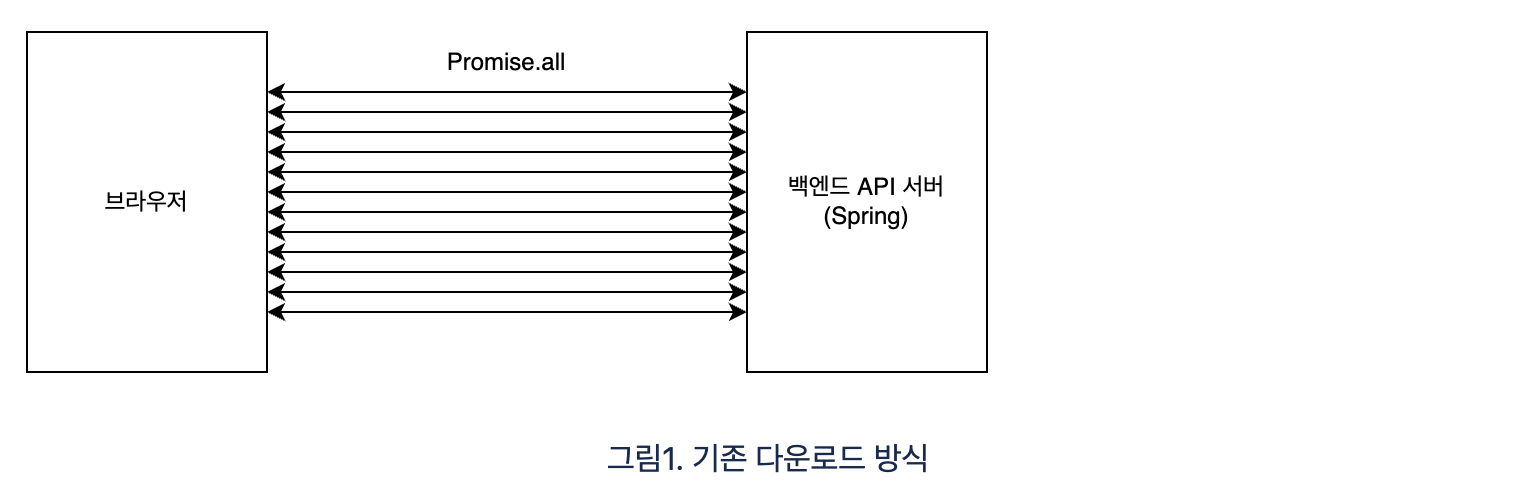
- 기존 모니터링 데이터를 가져오는 API는 페이지를 렌더링하기 위해 페이지네이션이 적용되어 있었습니다
- 따라서 엑셀로 구성하는 데이터 수에 비례해서 요청을 보내는 방식이었고 그 수가 많아지면 동시에 100건이 넘는 요청을 보내서 서버가 제대로 동작하지 못하는 이슈가 있었습니다
엑셀 다운로드 API 추가
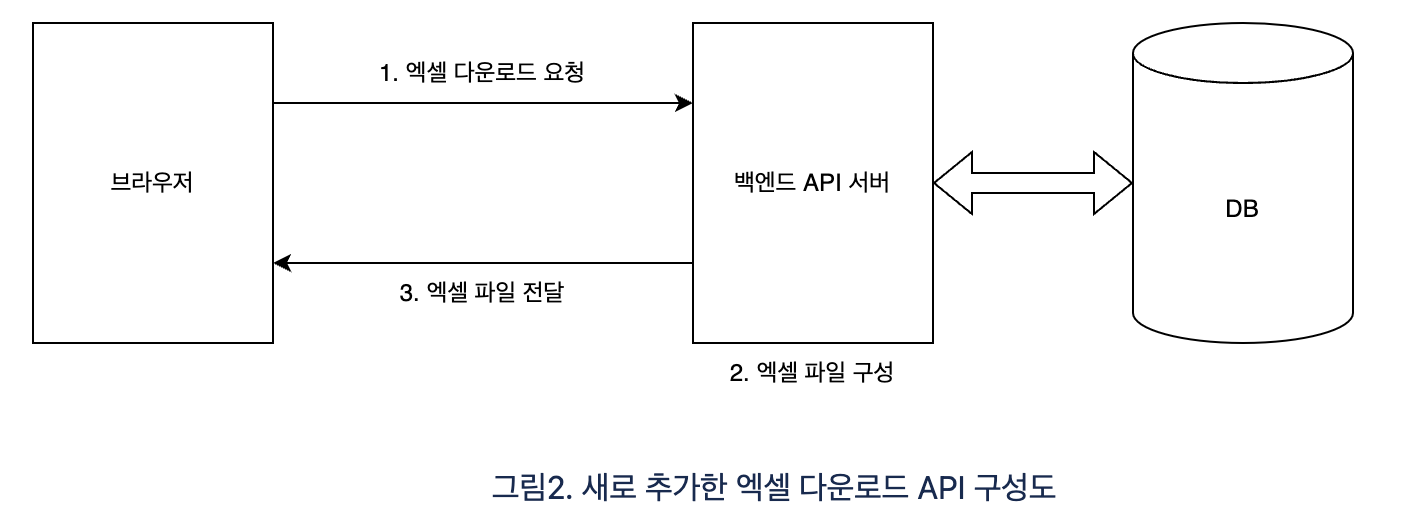
- 기존 문제점을 해결하기 위해 한번의 요청으로 백엔드 서버에서 엑셀 파일을 구성해서 내려주는 API를 추가하였습니다
- Java 라이브러리 중 Apachi POI를 사용했습니다(
XSSFWorkbook사용)
엑셀 다운로드 API 문제점

- 그림2와 같이 대량 데이터(e.g. 10만건)을 한번에 조회하는 경우 메모리 에러가 발생하는 것을 확인했습니다
- 현재 저희 개발서버는 0.5G 메모리를 가지고 있고 10만건 데이터를 처리하기에 메모리가 부족했습니다
- Spring은 최대 heap memory를 1/4까지 사용할 수 있습니다(0.5G / 4 => 125mb)
- 처음엔 단순히 개발 서버의 메모리를 올리는 것을 생각했지만 메모리 스펙을 늘리면 클라우드 비용이 증가하기 때문에 다른방식으로 해결해야 했습니다
엑셀 다운로드 API 개선
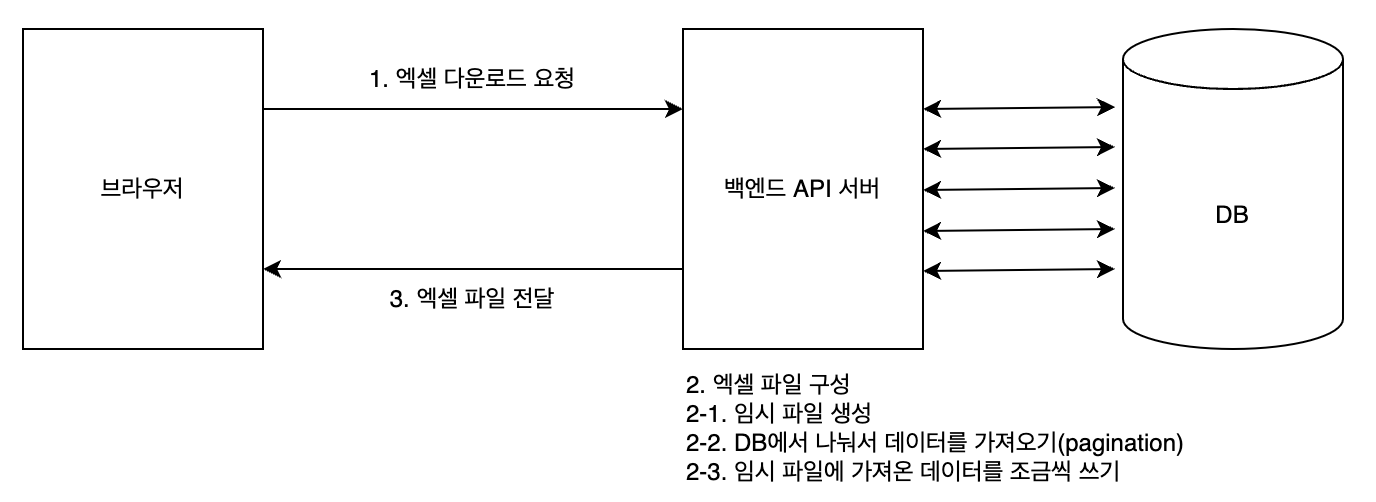
- 1. 엑셀 파일을 만들때 스트리밍 방식으로 작성
- 기존에
XSSFWorkbook대신 스트리밍 방식으로 만드는SXSSFWorkbook를 사용하였습니다 - 하지만 10만건 데이터를 메모리에서 가져와서 들고있는 단계에서 여전히 메모리 이슈가 발생했습니다
- 기존에
- 2. 데이터를 가져올 때 나눠서 가져오기
- 엑셀을 스트리밍 방식으로 만들 수 있으므로 데이터를 한번에 다 가져올 필요가 없게 되었습니다
- DB에서 데이터를 가져 올 때 페이지네이션을 적용해서 조금씩 가져와서 쓰는 방식으로 메모리 문제를 해결했습니다