배타적 서브타입(Exlusive Subtype) 테이블 설계와 백엔드 구현
배타적 서브타입이란?
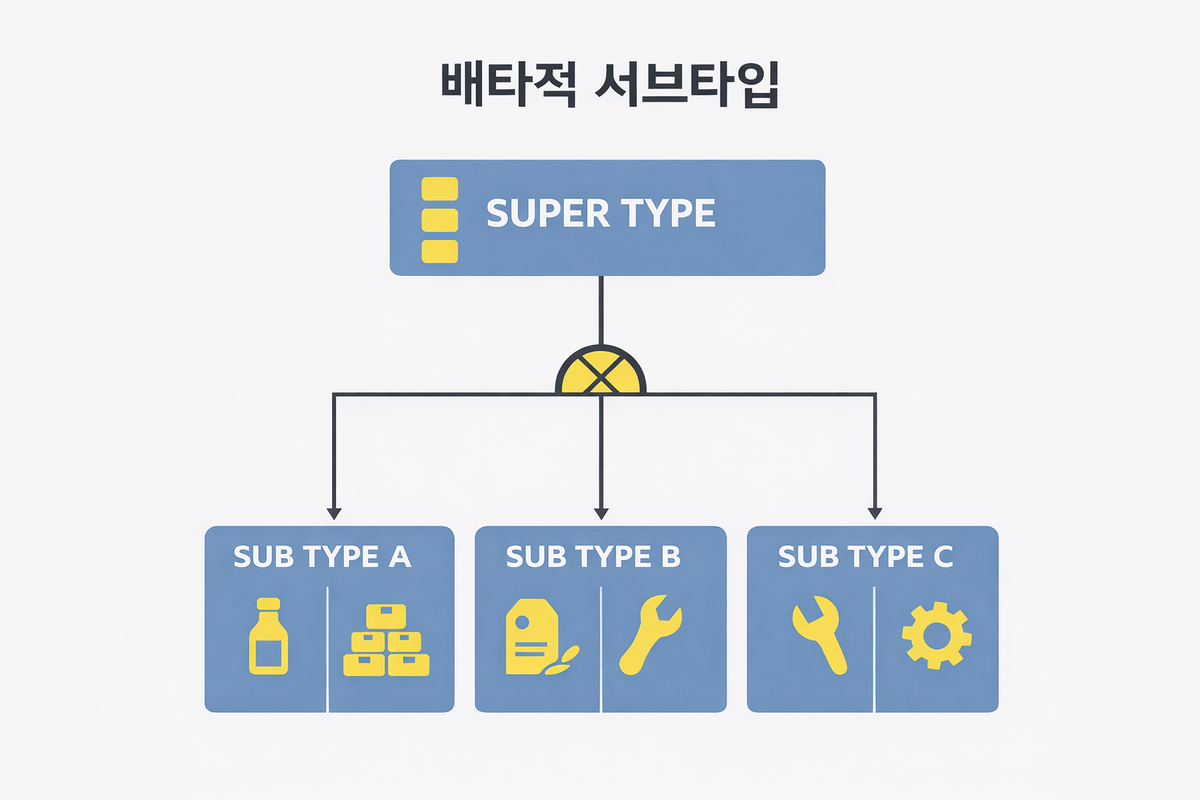
데이터베이스 테이블 설계에서 슈퍼타입(Super Type)과 서브타입(Sub Type)은 공통 속성을 기준으로 엔티티(테이블)를 상위/하위로 나누는 데이터 모델링 기법입니다.
- Super Type (상위 엔티티)
- 여러 엔티티가 공통으로 가지는 속성을 모아 놓은 엔티티
- 식별자(PK, ID)를 포함한 공통 정보를 가지고 있음
- Sub Type (하위 엔티티)
- 각 타입만의 고유한 속성을 추가로 가지는 엔티티
제조실행시스템(MES)를 위한 테이블을 설계 할 때를 예시로 왜 테이블을 Super Type과 Sub Type으로 나누는 지 살펴보겠습니다.
대표적으로 공장에서 제조를 할 때 사용되는 ITEM(품목)은 여러 종류가 있습니다.
- 제품(최종 제품)
- 반제품(제품을 생산 할 때 다른 필요한 중간 생산 제품)
- 자재
- 공구
위 현실세계의 제품을 엔티티로 모사해서 테이블 화 할 때 만약 위 다양한 종류를 하나의 엔티티로 관리한다면 NULL 컬럼이 급증하게 됩니다.
- NULL 컬럼이 급증하는 이유?
- 공구는 수명 및 점검주기 컬럼이 필요합니다.
- 자재는 자재에만 적용되는 스펙, 자재검사의 유무 등의 컬럼이 필요합니다.
- 제품은 제품의 최종적인 처리 방식을 나타내는 컬럼이 필요합니다.
위의 경우 하나의 테이블로 ITEM을 관리하게 되면 공구용 컬럼에는 자재, 제품 등의 데이터는 모두 NULL로 저장되며 반대의 경우도 발생합니다.
그렇다면 위 ITEM 별 종류들을 모두 별개의 엔티티로 관리하면 되지 않을까요? 그런 경우 다음과 같은 단점이 발생합니다.
- 공통속성이 여러 테이블에 중복됩니다.
- 제품/반제품/자재/공구 등은 모두 ITEM의 성격을 가지고 있어서 공통적으로 가지는 속성 예) 코드, 이름, 사용여부, 생성일, 수정일 등 이 테이블마다 중복으로 저장됩니다.
- 이 경우 공통 속성 컬럼 정의 수정 시 예)코드의 길이 변경 시 모든 종류의 ITEM 테이블 정의를 변경해야 합니다.
- ITEM이라는 공통 관점에서의 조회/참조가 어려워집니다.
- 만약 ITEM이라는 공통 속성으로만 조회를 할 경우, 테이블이 완전 분리되어 있으면 품목 검색 시 (공통컬럼만 필요한 경우에도)
제품/반제품/자재/공구를 각 각 조회하여UNION ALL로 합쳐야 합니다. - 또한 ITEM이라는 공통의 개념과 연관된 테이블을 설계할 때 다 수의
제품/반제품/자재/공구테이블과 각각 PK/FK 관계를 맺을 필요 없이 ITEM 슈퍼타입의 ITEM_ID를 FK로 한번 참조할 수 있습니다.
- 만약 ITEM이라는 공통 속성으로만 조회를 할 경우, 테이블이 완전 분리되어 있으면 품목 검색 시 (공통컬럼만 필요한 경우에도)
- 제품/반제품/자재/공구 등은 모두 ITEM의 성격을 가지고 있어서 공통적으로 가지는 속성 예) 코드, 이름, 사용여부, 생성일, 수정일 등 이 테이블마다 중복으로 저장됩니다.
이런 단점들을 보완하기 위해 Super Type으로 ITEM(품목) 엔티티를 설정하고 Sub Type으로 각 각 제품, 반제품, 자재, 공구 등의 엔티티를 설계할 수 있습니다. 이 경우 공통 컬럼은 Super Type인 ITEM(품목) 엔티티에 설정하고 각 Sub Type의 고유 특성들을 각 각의 엔티티에 설정해서 관리 해주면 됩니다.
그런데 배타적 - exclusive 라는 말이 왜 붙은 걸까요?
여기서 배타적이라는 의미는 ITEM(품목) 이 무조건 제품, 또는 자재 등의 하위 성격중에서 하나만 가지고 있어야 된다는 의미입니다. 만약 ITEM_ID 로 ITEM_001이라는 데이터가 제품이자 자재여서 제품 Sub-Type entity에도 저장되고, 자재 Sub-Type entity에도 저장되면 안된다는 의미 입니다.
만약 ITEM_ID = 'ITEM_001' 인 데이터가
PRODUCT 테이블과 MATERIAL 테이블에 동시에 존재한다면,
해당 ITEM은 “제품이면서 자재”가 되어버리며
이는 우리가 정의한 품목의 도메인 규칙을 명확히 위반하는 상태가 됩니다.
이처럼 서브타입 간 중복을 허용하지 않고,
반드시 하나의 하위 성격만 가질 수 있도록 제한하는 구조를
배타적(Exclusive) 서브타입이라고 부릅니다.
이처럼 배타적으로 설계 하지 않을 경우에는 아래와 같은 단점이 존재합니다.
- 도메인 의미가 깨집니다.
- MES 관점에서 제품, 자재, 공구는 역할과 책임이 전혀 다른 개념입니다.
- 제품은 생산의 결과물이며 출하 대상이 되고
- 자재는 생산에 투입되어 소모되며
- 공구는 수명을 관리하며 반복 사용됩니다.
- 그런데 하나의 ITEM이 제품이면서 동시에 자재로 존재한다면, 이 ITEM이
출하대상인지소모대상인지 명확하지 않게 됩니다.
- MES 관점에서 제품, 자재, 공구는 역할과 책임이 전혀 다른 개념입니다.
- 분기문이 복잡해집니다.
- 만약 ITEM이 여러 Sub Type에 동시에 존재 할 수 있다면, 백엔드 로직은 항상 다음과 같은 방어 코드를 작성해주어야 합니다
- 이 ITEM은 제품이기도 하고 자재이기도 합니다.
- 이 ITEM을 어떤 기준으로 제품으로 처리할 지, 자재로 처리할 지 모호합니다.
- 결국 코드 곳곳에 아래와 같은 분기문이 생기게 됩니다.
- 만약 ITEM이 여러 Sub Type에 동시에 존재 할 수 있다면, 백엔드 로직은 항상 다음과 같은 방어 코드를 작성해주어야 합니다
if (isProduct && isMaterial) {
...
}배타적 서브타입 설계 예시
그럼 실제로 배타적 서브타입 설계 + 백엔드 구현을 해보겠습니다.
데이터베이스 구현
먼저 테스트 환경은 데이터베이스 서버는 MS SQL SERVER 15버전이며 데이터베이스 관리 및 쿼리 툴은 SQL Server Management Studio 18.12.1 버전 입니다.
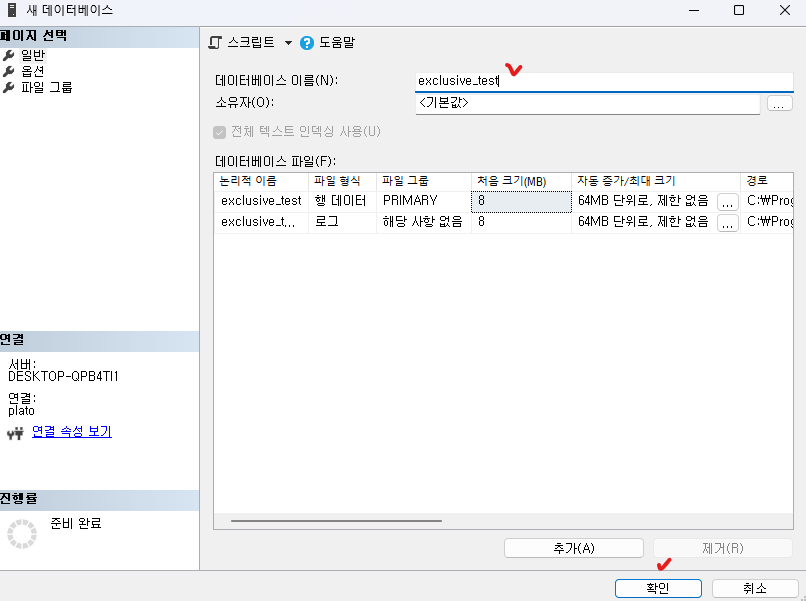
테스트용 데이터데이스를 생성해보겠습니다.
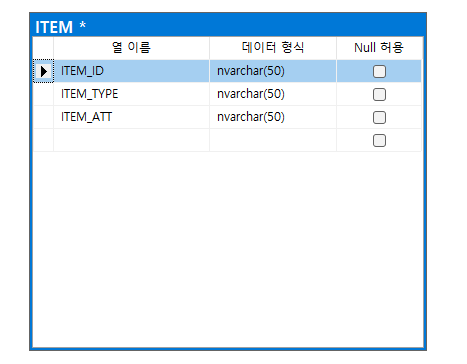
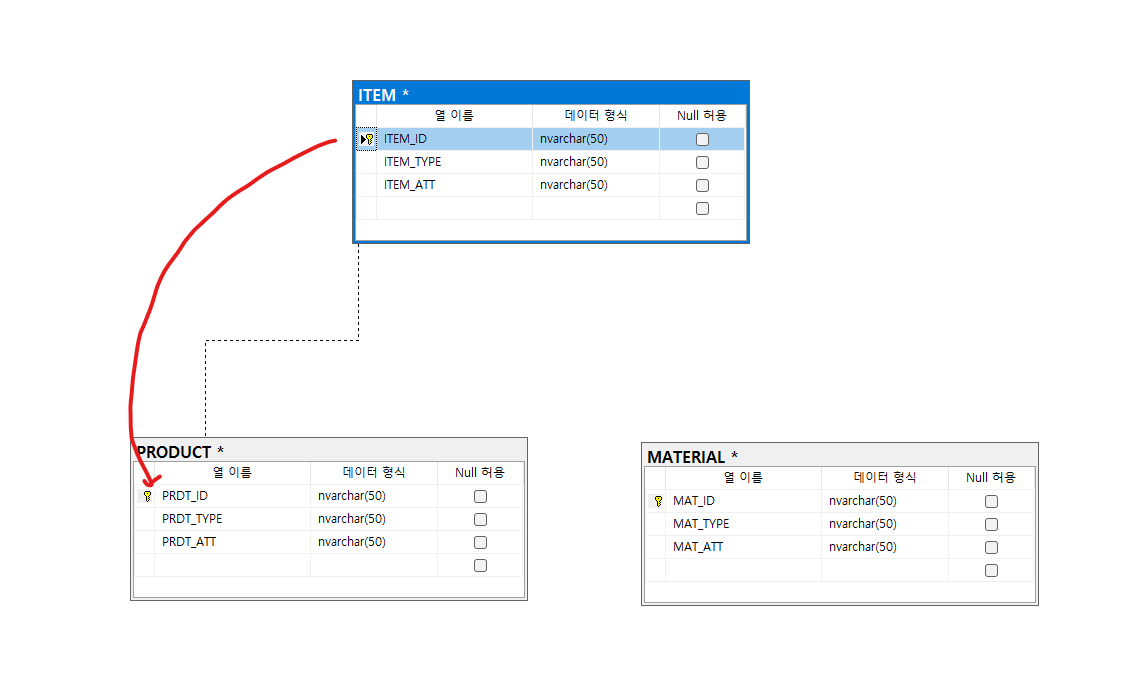
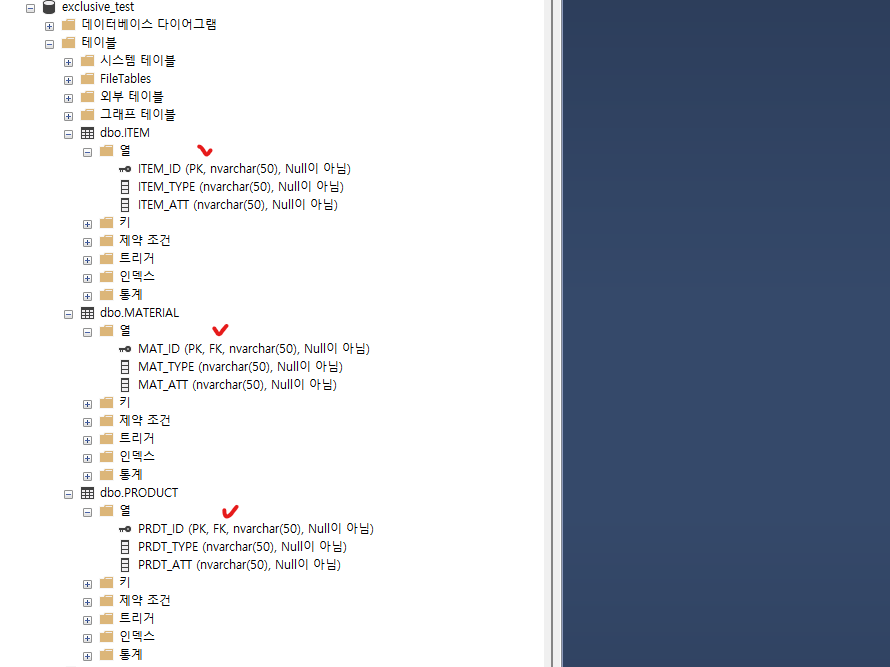
생성된 데이터베이스에 각 각 Super Type으로 ITEM(품목)을 Sub Type으로 PRODUCT(제품), MATERIAL(자재) 테이블을 추가 해줍니다.
- Super Type
- ITEM(품목)
- ITEM_ID (PK)
- ITEM_TYPE (타입)
- ITEM_ATT (공통속성)
- ITEM(품목)
- Sub Type
- PRODUCT(제품)
- PRDT_ID (PK,FK)
- PRDT_TYPE (타입)
- PRDT_ATT (고유속성)
- MATERIAL(자재)
- MAT_ID (PK,FK)
- MAT_TYPE (타입)
- MAT_ATT (고유속성)
- PRODUCT(제품)
테이블 생성 및 연관관계 설정은 데이터베이스 관리 툴에서 -> 데이터베이스 다이어그램 기능(우클릭-새 데이터베이스 다이어그램)을 이용해서 생성하겠습니다.

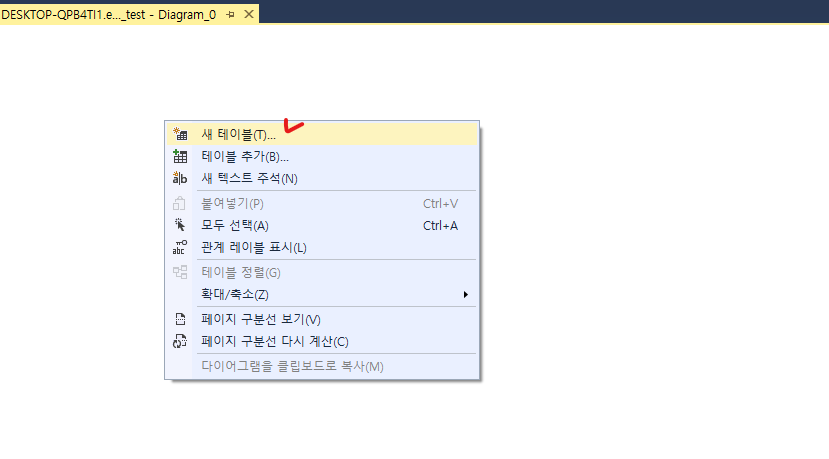
다이어그램 창 -> 우클릭 -> 새 테이블
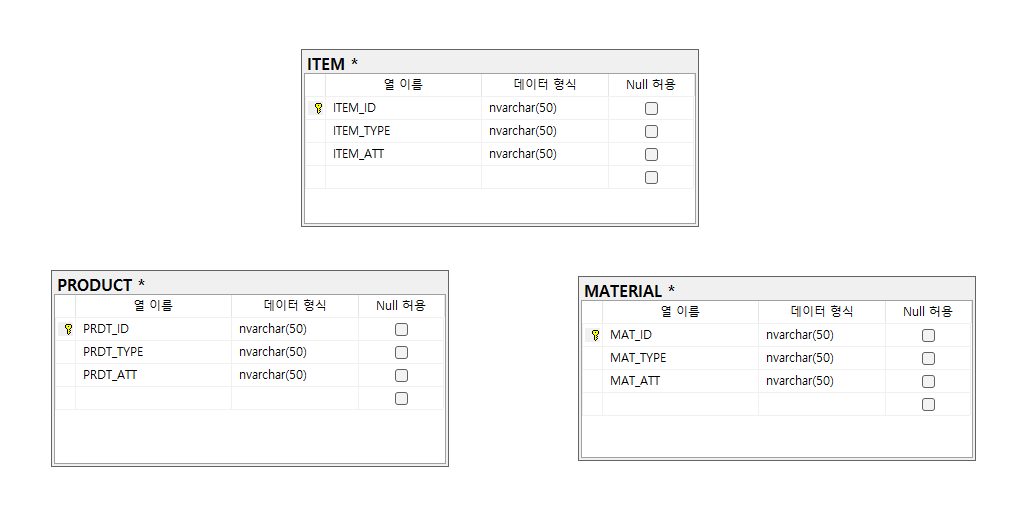
이제 연관관계를 설정해줍니다. Sub Type의 PK인 PRDT_ID와 MAT_ID의 FK를 ITEM의 PK로 지정합니다.
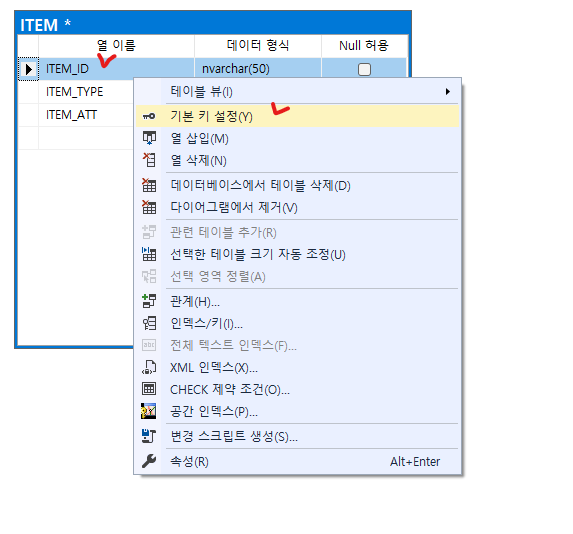
먼저 ITEM 테이블의 PRIMARY KEY 칼럼인 ITEM ID의 열쇠 아이콘을 마우스 좌 클릭 후 PRODUCT 테이블의 PRIMARY 칼럼인 PRDT_ID 칼럼으로 끌어다 놓습니다.
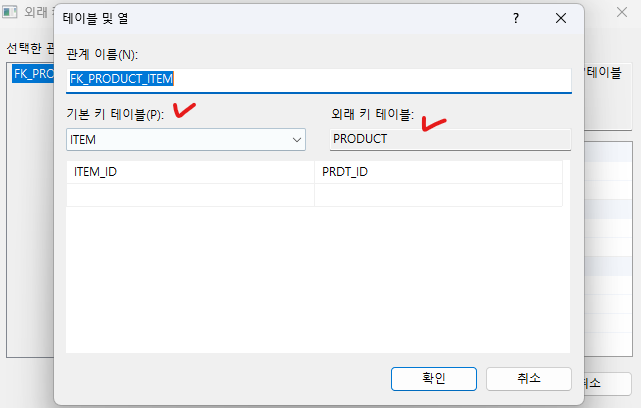
MATERIAL 테이블도 똑같이 해줍니다.
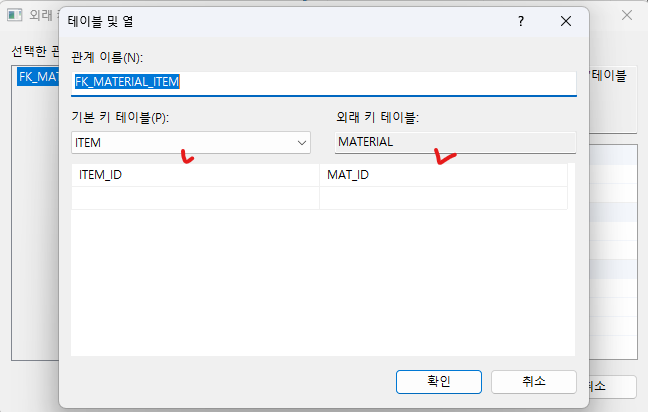
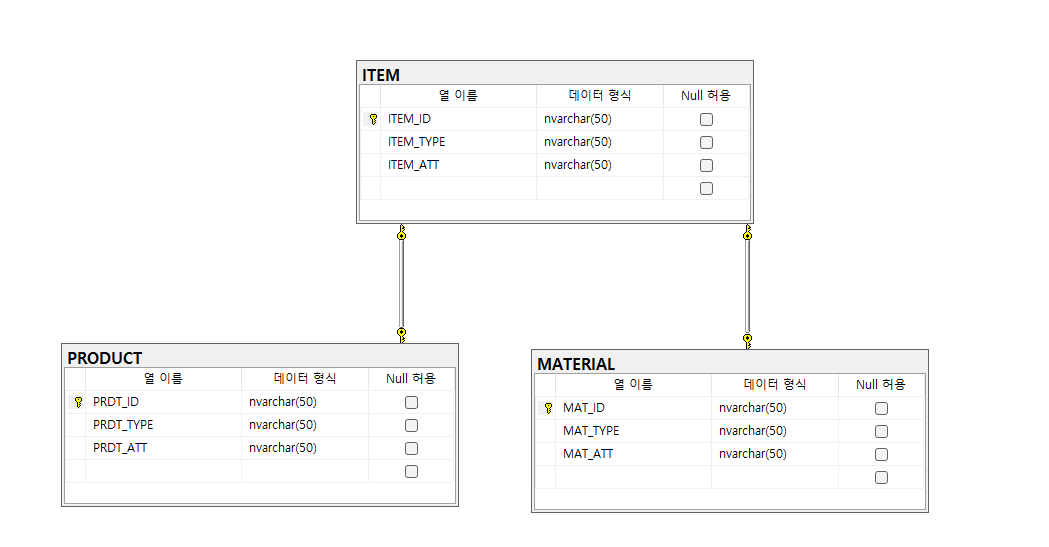
해당 다이어그램을 저장(ctrl + s)하여 실제 테이블이 생성됨을 확인합니다.
주의: 운영환경의 데이터베이스에서 다이어그램툴을 이용하여 수정, 생성 후 저장은 실제로 데이터베이스에 반영이 되므로 주의해야 합니다.
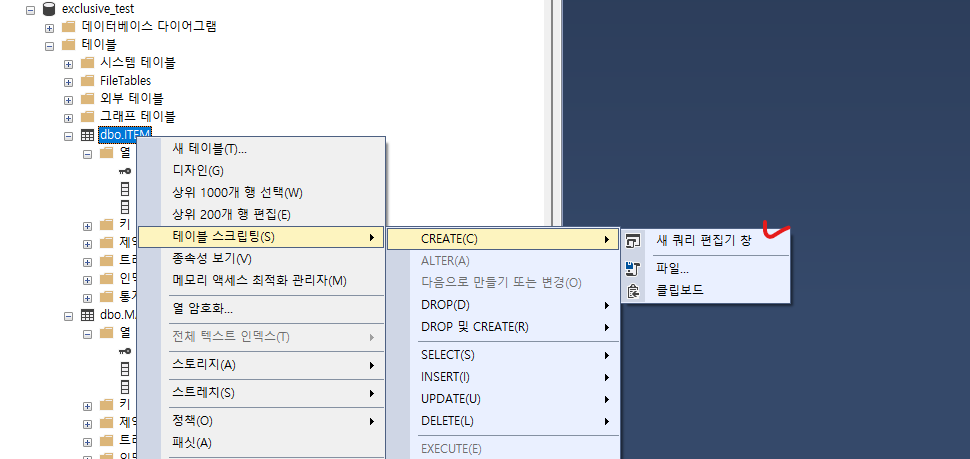
생성된 테이블의 CREATE 문을 살펴보겠습니다.
- Super Type
USE [exclusive_test]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[ITEM](
[ITEM_ID] [nvarchar](50) NOT NULL,
[ITEM_TYPE] [nvarchar](50) NOT NULL,
[ITEM_ATT] [nvarchar](50) NOT NULL,
CONSTRAINT [PK_ITEM] PRIMARY KEY CLUSTERED
(
[ITEM_ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
GO단순화 버전
CREATE TABLE ITEM (
ITEM_ID NVARCHAR(50) PRIMARY KEY,
ITEM_TYPE NVARCHAR(50) NOT NULL,
ITEM_ATT NVARCHAR(50) NOT NULL
);- Sub Type
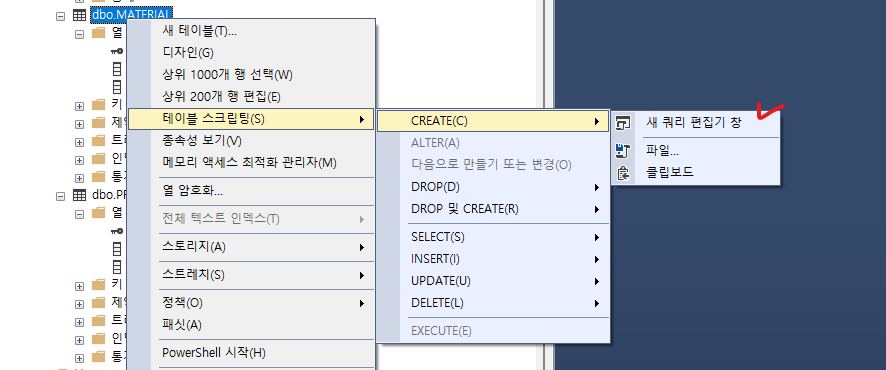
USE [exclusive_test]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[MATERIAL](
[MAT_ID] [nvarchar](50) NOT NULL,
[MAT_TYPE] [nvarchar](50) NOT NULL,
[MAT_ATT] [nvarchar](50) NOT NULL,
CONSTRAINT [PK_MATERIAL] PRIMARY KEY CLUSTERED
(
[MAT_ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[MATERIAL] WITH CHECK ADD CONSTRAINT [FK_MATERIAL_ITEM] FOREIGN KEY([MAT_ID])
REFERENCES [dbo].[ITEM] ([ITEM_ID])
GO
ALTER TABLE [dbo].[MATERIAL] CHECK CONSTRAINT [FK_MATERIAL_ITEM]
GO단순화 버전
CREATE TABLE MATERIAL (
MAT_ID NVARCHAR(50) PRIMARY KEY,
MAT_TYPE NVARCHAR(50) NOT NULL,
MAT_ATT NVARCHAR(50) NOT NULL,
CONSTRAINT FK_MATERIAL_ITEM
FOREIGN KEY (MAT_ID)
REFERENCES ITEM (ITEM_ID)
);백엔드 구현
이제 해당 데이터베이스 테이블들에 데이터를 저장, 조회 하는 백엔드 예시 코드를 구현해보겠습니다.
먼저, 우리가 구현한 데이터베이스 테이블 설계에서 한가지 의문점을 가져야 합니다.
과연 저 데이터베이스 테이블 설계 구조에서 위에서 언급된 배타적 특성이 보장되는지 입니다.
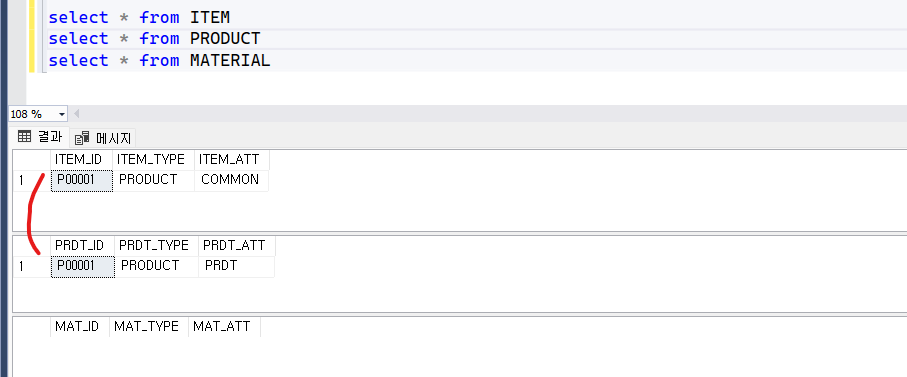
결론적으로 지금 상태에서는 배타적 특성이 보장되지 않습니다. 예시로 위 설계된 테이블에 데이터를 넣어 보겠습니다.
정상 케이스
-- 슈퍼타입 생성
INSERT INTO ITEM (ITEM_ID, ITEM_TYPE, ITEM_ATT)
VALUES ('ITM001', 'PRDT', 'COMMON');
-- PRODUCT 서브타입 생성 (OK)
INSERT INTO PRODUCT (PRDT_ID, PRDT_TYPE, PRDT_ATT)
VALUES ('ITM001', 'PRDT', 'PRDT');배타성이 깨진 케이스
INSERT INTO MATERIAL (MAT_ID, MAT_TYPE, MAT_ATT)
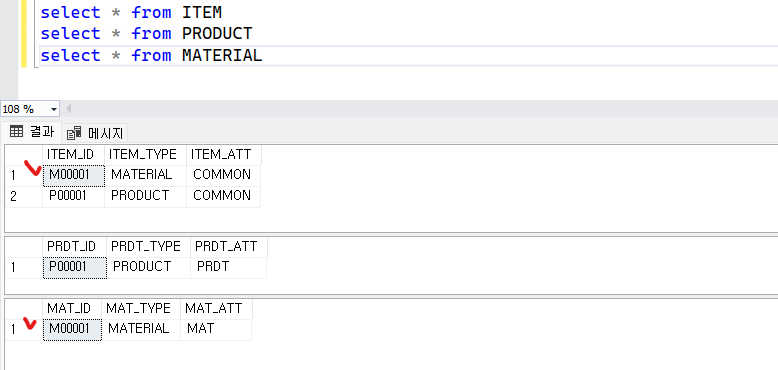
VALUES ('ITM001', 'MAT', 'MAT');조회 해봅니다.
select * from ITEM
select * from PRODUCT
select * from MATERIAL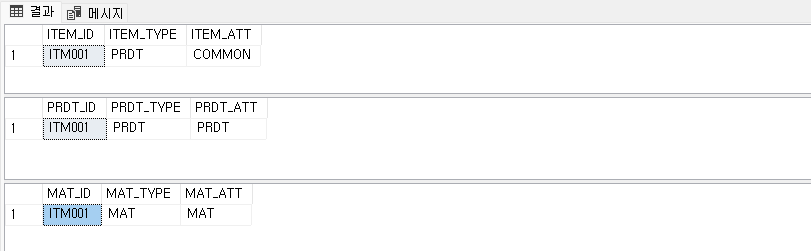
왜 이런 결과가 발생할까요?
- FOREIGN KEY는
→ “부모가 존재하는지”만 검증한다. - PRIMARY KEY는
→ “중복되지 않는지”만 보장한다.
하지만 DB 제약만으로는,
- “이 ITEM_ID가 어느 Sub Type에 속하는지”
- “이미 다른 Sub Type에 속해 있는지”
와 같은 도메인 규칙까지 표현하기는 어렵습니다.
물론, 트리거(trigger)나 복잡한 제약조건을 걸어 일부 제어는 가능하지만 실무에서는 배타성의 최종 책임을 백엔드 애플리케이션 이 가져가는 경우다 대부분입니다.
이에 따라 백엔드 구현 예시는 어떻게 배타성을 적용하는지의 관점으로 작성되었습니다.
- 백엔드 환경
- java 17
- spring boot 3.5.10
spring.application.name=exclu_demo
#Hikari CP
spring.datasource.max-lifetime=1800000
spring.datasource.maximum-pool-size=20
#JPA
spring.jpa.hibernate.ddl-auto=none
# MS-SQL config
spring.datasource.driver-class-name=com.microsoft.sqlserver.jdbc.SQLServerDriver
spring.datasource.url=jdbc:sqlserver://127.0.0.1;databaseName=exclusive_test;trustServerCertificate=true
spring.datasource.username=plato
spring.datasource.password=먼저 DB 테이블 매핑하는 코드를 작성하겠습니다.entity 폴더를 만들고 우리가 생성한 테이블과 매핑 되는 Item Product Material 코드를 작성합니다.

package plato.io.exclu_demo.entity;
import jakarta.persistence.*;
import lombok.*;
import org.springframework.data.domain.Persistable;
import java.io.Serializable;
@Entity
@Table(name = "ITEM")
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class Item implements Persistable<String>, Serializable {
@Id
@Column(name = "ITEM_ID", length = 50 )
private String itemId;
@Enumerated(EnumType.STRING)
@Column(name = "ITEM_TYPE", length = 50)
private ItemType itemType;
@Column(name = "ITEM_ATT", length = 50)
private String itemAtt;
@Override
public String getId() {
return itemId;
}
@Override
public boolean isNew() {
return false;
}
@Setter
@Transient
@Builder.Default
private boolean isNew = false;
}
package plato.io.exclu_demo.entity;
import jakarta.persistence.*;
import lombok.*;
import org.springframework.data.domain.Persistable;
import java.io.Serializable;
@Entity
@Table(name = "PRODUCT")
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class Product implements Persistable<String>, Serializable {
@Id
@Column(name = "PRDT_ID", length = 50)
private String prdtId;
@Enumerated(EnumType.STRING)
@Column(name = "PRDT_TYPE", length = 50)
private ItemType prdtType;
@Column(name = "PRDT_ATT", length = 50)
private String prdtAtt;
// 부모(Item) 참조 - FK
@OneToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "PRDT_ID", referencedColumnName = "ITEM_ID", insertable = false, updatable = false)
private Item item;
@Transient
@Builder.Default
private boolean isNew = false;
@Override
public String getId() {
return prdtId;
}
@Override
public boolean isNew() {
return isNew;
}
}
package plato.io.exclu_demo.entity;
import jakarta.persistence.*;
import lombok.*;
import org.springframework.data.domain.Persistable;
import java.io.Serializable;
@Entity
@Table(name = "MATERIAL")
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class Material implements Persistable<String>, Serializable {
@Id
@Column(name = "MAT_ID", length = 50)
private String matId;
@Enumerated(EnumType.STRING)
@Column(name = "MAT_TYPE", length = 50)
private ItemType matType;
@Column(name = "MAT_ATT", length = 50)
private String matAtt;
// 부모(Item) 참조 - FK
@OneToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "MAT_ID", referencedColumnName = "ITEM_ID", insertable = false, updatable = false)
private Item item;
@Transient
@Builder.Default
private boolean isNew = false;
@Override
public String getId() {
return matId;
}
@Override
public boolean isNew() {
return isNew;
}
}
ItemType enum 클래스도 생성해줍니다.
package plato.io.exclu_demo.entity;
import lombok.Getter;
import lombok.RequiredArgsConstructor;
@Getter
@RequiredArgsConstructor
public enum ItemType {
PRODUCT("P", "제품"),
MATERIAL("M", "자재");
private final String prefix; // ID prefix
private final String description; // 설명
}
그 다음 repository 계층을 인터페이스로 선언해줍니다.
package plato.io.exclu_demo.repository;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
import plato.io.exclu_demo.entity.Item;
import java.util.List;
@Repository
public interface ItemRepository extends JpaRepository<Item, String> {
}
package plato.io.exclu_demo.repository;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
import plato.io.exclu_demo.entity.Product;
@Repository
public interface ProductRepository extends JpaRepository<Product,String> {
}
package plato.io.exclu_demo.repository;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
import plato.io.exclu_demo.entity.Material;
@Repository
public interface MaterialRepository extends JpaRepository<Material,String> {
}
다음으로 ITEM 생성시 필요한 DTO 구조를 작성합니다.
package plato.io.exclu_demo.dto;
import lombok.*;
import plato.io.exclu_demo.entity.ItemType;
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class ItemSaveRequest {
// 공통 (ITEM)
private ItemType itemType;
private String itemAtt;
// 제품 (PRODUCT)
private String prdtAtt;
// 자재 (MATERIAL)
private String matAtt;
}
package plato.io.exclu_demo.dto;
import lombok.Builder;
import lombok.Getter;
import plato.io.exclu_demo.entity.Item;
import plato.io.exclu_demo.entity.ItemType;
@Getter
@Builder
public class ItemSaveResponse {
private String itemId;
private ItemType itemType;
private String itemAtt;
public static ItemSaveResponse from(Item item) {
return ItemSaveResponse.builder()
.itemId(item.getItemId())
.itemType(item.getItemType())
.itemAtt(item.getItemAtt())
.build();
}
}
다음으로 실제 ITEM/제품/자재를 저장, 조회하는 service 계층입니다.
package plato.io.exclu_demo.service;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import plato.io.exclu_demo.dto.ItemSaveRequest;
import plato.io.exclu_demo.dto.ItemSaveResponse;
import plato.io.exclu_demo.entity.Item;
import plato.io.exclu_demo.entity.ItemType;
import plato.io.exclu_demo.entity.Material;
import plato.io.exclu_demo.entity.Product;
import plato.io.exclu_demo.repository.ItemRepository;
import plato.io.exclu_demo.repository.MaterialRepository;
import plato.io.exclu_demo.repository.ProductRepository;
@Service
@RequiredArgsConstructor
@Transactional
public class ItemService {
private final ItemRepository itemRepository;
private final ProductRepository productRepository;
private final MaterialRepository materialRepository;
/**
* ITEM_TYPE에 따라 ID 자동 생성
*/
private String generateId(ItemType itemType) {
long count = switch (itemType) {
case PRODUCT -> productRepository.count();
case MATERIAL -> materialRepository.count();
};
return itemType.getPrefix() + String.format("%05d", count + 1);
}
/**
* 품목 저장 - ITEM_TYPE에 따라 서브타입 자동 생성
*/
public ItemSaveResponse saveItem(ItemSaveRequest request) {
ItemType itemType = request.getItemType();
// 1. ID 자동 생성
String itemId = generateId(itemType);
// 2. Super Type 생성
Item item = Item.builder()
.itemId(itemId)
.itemType(itemType)
.itemAtt(request.getItemAtt())
.build();
item.setNew(true);
// 3. Item 먼저 저장
itemRepository.save(item);
// 4. ITEM_TYPE에 따라 Sub Type 생성 및 저장 (배타적)
switch (itemType) {
case PRODUCT -> {
Product product = Product.builder()
.prdtId(itemId)
.prdtType(itemType)
.prdtAtt(request.getPrdtAtt())
.build();
product.setNew(true);
productRepository.save(product);
}
case MATERIAL -> {
Material material = Material.builder()
.matId(itemId)
.matType(itemType)
.matAtt(request.getMatAtt())
.build();
material.setNew(true);
materialRepository.save(material);
}
}
return ItemSaveResponse.from(item);
}
}
다음으로 controller 계층을 만듭니다.
package plato.io.exclu_demo.controller;
import lombok.RequiredArgsConstructor;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import plato.io.exclu_demo.dto.ItemSaveRequest;
import plato.io.exclu_demo.dto.ItemSaveResponse;
import plato.io.exclu_demo.service.ItemService;
@RestController
@RequestMapping("/api/item")
@RequiredArgsConstructor
public class ItemController {
private final ItemService itemService;
@PostMapping
public ResponseEntity<ItemSaveResponse> saveItem(@RequestBody ItemSaveRequest request) {
ItemSaveResponse response = itemService.saveItem(request);
return ResponseEntity.ok(response);
}
}
테스트를 해봅니다.
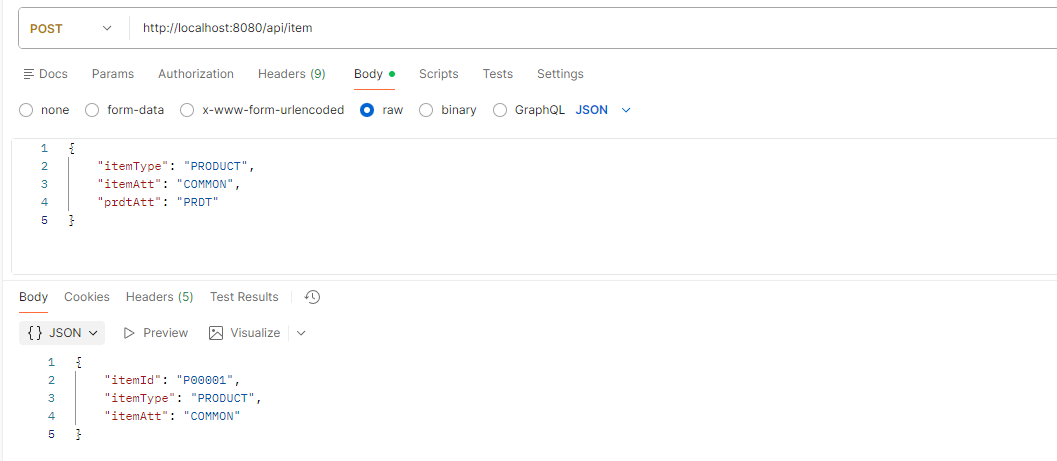
- 제품 저장
POST http://localhost:8080/api/item
{
"itemType": "PRODUCT",
"itemAtt": "COMMON",
"prdtAtt": "PRDT"
}
- 자재 저장
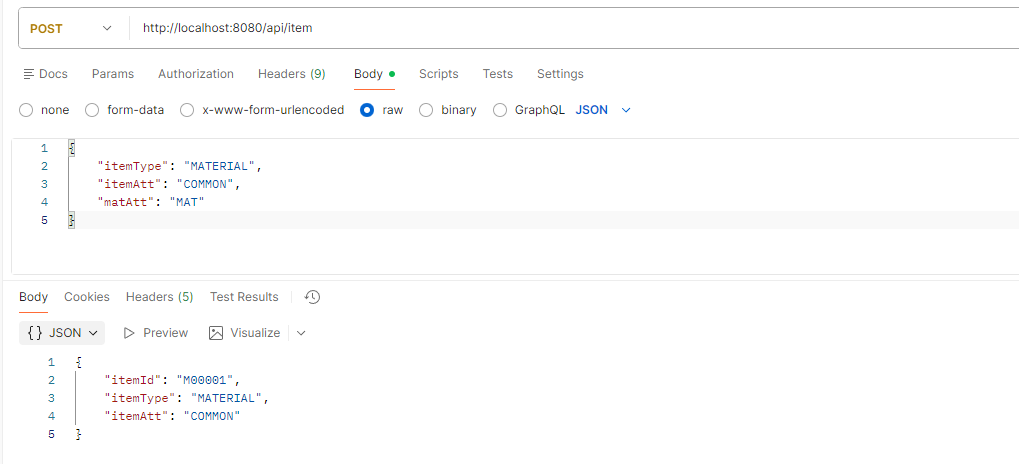
POST http://localhost:8080/api/item
{
"itemType": "MATERIAL",
"itemAtt": "COMMON",
"matAtt": "MAT"
}